Predictive Scaling in MongoDB Atlas, an Experiment
At MongoDB, we experimented to see if we could predict each DBaaS customer’s demand fluctuations, and auto-scale them using this foreknowledge. Senior Data Scientist Matthieu Humeau and I spoke about this experiment at Data Council and NYC Systems. Here’s the video from NYC Systems, and a written version is below.
Replica Sets #
MongoDB is generally deployed as a group of servers, where one is the primary and at least two are secondaries. The client sends all writes to the primary, and the secondaries replicate those writes, usually within milliseconds. The client can read from the primary or the secondaries. So secondaries can take some of the query load, and they’re hot standbys. If the primary fails, a secondary automatically becomes primary within a few seconds, with zero data loss.

MongoDB replica set.
Atlas #
MongoDB is free and open source, you can download it and deploy a replica set yourself, and lots of people do. But these days people mostly use our cloud service, MongoDB Atlas. Atlas started out as a database-as-a-service. Now we call it a Developer Data Platform because it offers a lot more than a database; we have triggers and events and streaming analysis and edge computing and vector search. But this experiment focuses on the DBaaS.
The DBaaS is multi-region—customers can spread their data around the world or locate it close to their users—and it’s multi-cloud, it runs on AWS, GCP, and Azure. A customer can even deploy a replica set that includes servers in multiple clouds at once.
MongoDB’s cloud is actually Amazon’s, Microsoft’s, or Google’s cloud.

MongoDB’s secret business model (not drawn to scale).
Atlas customers decide how many MongoDB servers to deploy in Atlas, what clouds to deploy them in, and what size of server: how many CPUs, how much RAM, and so on. Each server in a replica set must use the same tier. (With exceptions.) We charge customers according to their choices: how many servers, what size, and how many hours they’re running. Of course, most of the money we charge our customers, we then pay to the underlying cloud providers. Those providers charge us according to the number and size of servers and how long they’re running. If we could save money by anticipating each customer’s needs and perfectly scaling their server sizes up and down, according to their changing demands, that would save our customers money and reduce our carbon emissions.
| Tier | Storage | RAM | vCPUs | Base Price |
|---|---|---|---|---|
| M10 | 10 GB | 2 GB | 2 vCPUs | $0.08/hr |
| M20 | 20 GB | 4 GB | 2 vCPUs | $0.20/hr |
| M30 | 40 GB | 8 GB | 2 vCPUs | $0.54/hr |
| M40 | 80 GB | 16 GB | 4 vCPUs | $1.04/hr |
| M50 | 160 GB | 32 GB | 8 vCPUs | $2.00/hr |
| M60 | 320 GB | 64 GB | 16 vCPUs | $3.95/hr |
| M80 | 750 GB | 128 GB | 32 vCPUs | $7.30/hr |
| M140 | 1000 GB | 192 GB | 48 vCPUs | $10.99/hr |
| M200 | 1500 GB | 256 GB | 64 vCPUs | $14.59/hr |
| M300 | 2000 GB | 384 GB | 96 vCPUs | $21.85/hr |
| M400 | 3000 GB | 488 GB | 64 vCPUs | $22.40/hr |
| M700 | 4000 GB | 768 GB | 96 vCPUs | $33.26/hr |
We sell MongoDB server sizes as a set of “tiers”, those are named like M10, M20, and so on, on the left. Those map to specific instance sizes in the cloud provider, so an M10 is a certain size of AWS server, and we charge a certain price on AWS. If the customer chooses to deploy their M10 on Azure or GCP then the size and price will be slightly different.
Manually-Triggered Scaling #
A customer can change their server size with zero downtime. Here’s the process:
- The customer clicks a button or executes an API call to resize their servers to a chosen tier.
- Atlas chooses a secondary and takes it offline,
- detaches its network storage,
- restarts it with a different server size,
- reattaches the storage,
- and waits for it to catch up to the primary, by replaying all the writes it missed while it was down.
- Atlas scales the other secondary likewise.
- Atlas tells the primary to become a secondary and hand off its responsibilities to another server.
- Atlas scales the former primary.

The whole process takes about 15 minutes, and the customer can read and write their data normally throughout. Usually the customer’s application doesn’t even notice the scaling operation, except that once scaling is complete, performance is faster or slower, and the price is different.
Atlas Autoscaling Today #

Atlas customers can opt in to autoscaling, but today’s autoscaling is infrequent and reactive. The rules are:
- scale up by one tier after 1 hour of overload,
- scale down by one tier after 4 hours of underload.
Overload is defined as over 75% CPU or RAM utilization, and underload is less than 50% of either. (Details here.) Atlas only scales between adjacent tiers, e.g. if an M60 replica set is underloaded, Atlas will scale it down to M50, but not directly to any tier smaller than that. If the customer’s demand changes dramatically, it takes several scaling operations to reach the optimum server size. This means servers can be overloaded or underloaded for long periods! An underloaded server is a waste of money. An overloaded server is bad for performance, and if it’s really slammed it could interfere with the scaling operation itself. So Matthieu and I envisioned…
The Ideal Future #

In the ideal future, we would forecast each replica set’s resource needs. We could scale a replica set up just before it’s overloaded, and scale it down as soon as it’s underloaded. We would scale it directly to the right server size, skipping intermediate tiers. We’d always use the cheapest size that could meet the customer’s demand.
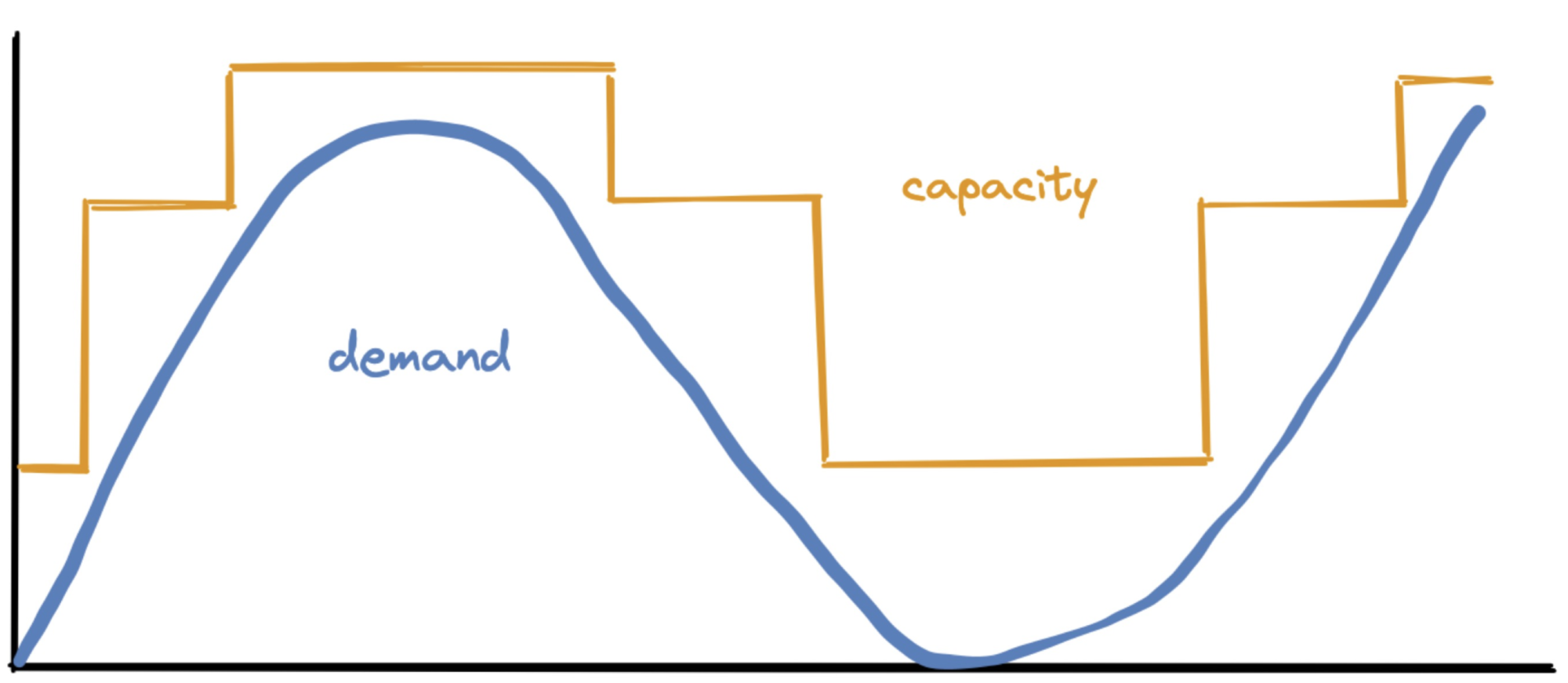
Predictive Scaling Experiment #
Matthieu and I performed an experiment over the last year to see if predictive scaling was possible in the MongoDB Atlas DBaaS.
The experiment was possible because Atlas keeps servers’ performance metrics in a data warehouse. We have a couple of years of data about all servers’ CPU and memory utilization, the numbers of queries per second, inserts per second, etc., all at one-minute intervals. Atlas has about 170,000 replica sets now, each with at least three servers, so it’s a stout data set. We chose 10,000 replica sets where customers had opted in to the existing reactive auto-scaler, and we analyzed their 2023 history. We split the history into a training period and a testing period, as usual with machine learning, and trained models to forecast the clusters’ demand and CPU utilization. (CPU is the simplest and most important metric; eventually we’ll forecast RAM, disk I/O, and so on.) Once we’d prototyped this predictive scaler, we estimated how it would’ve performed during the testing period, compared to the reactive scaler that was running at that time.
The prototype had three components:
- Forecaster: tries to predict each cluster’s future workload.
- Estimator: estimates CPU% for any workload, any instance size.
- Planner: chooses cheapest instance that satisfies forecasted demand.
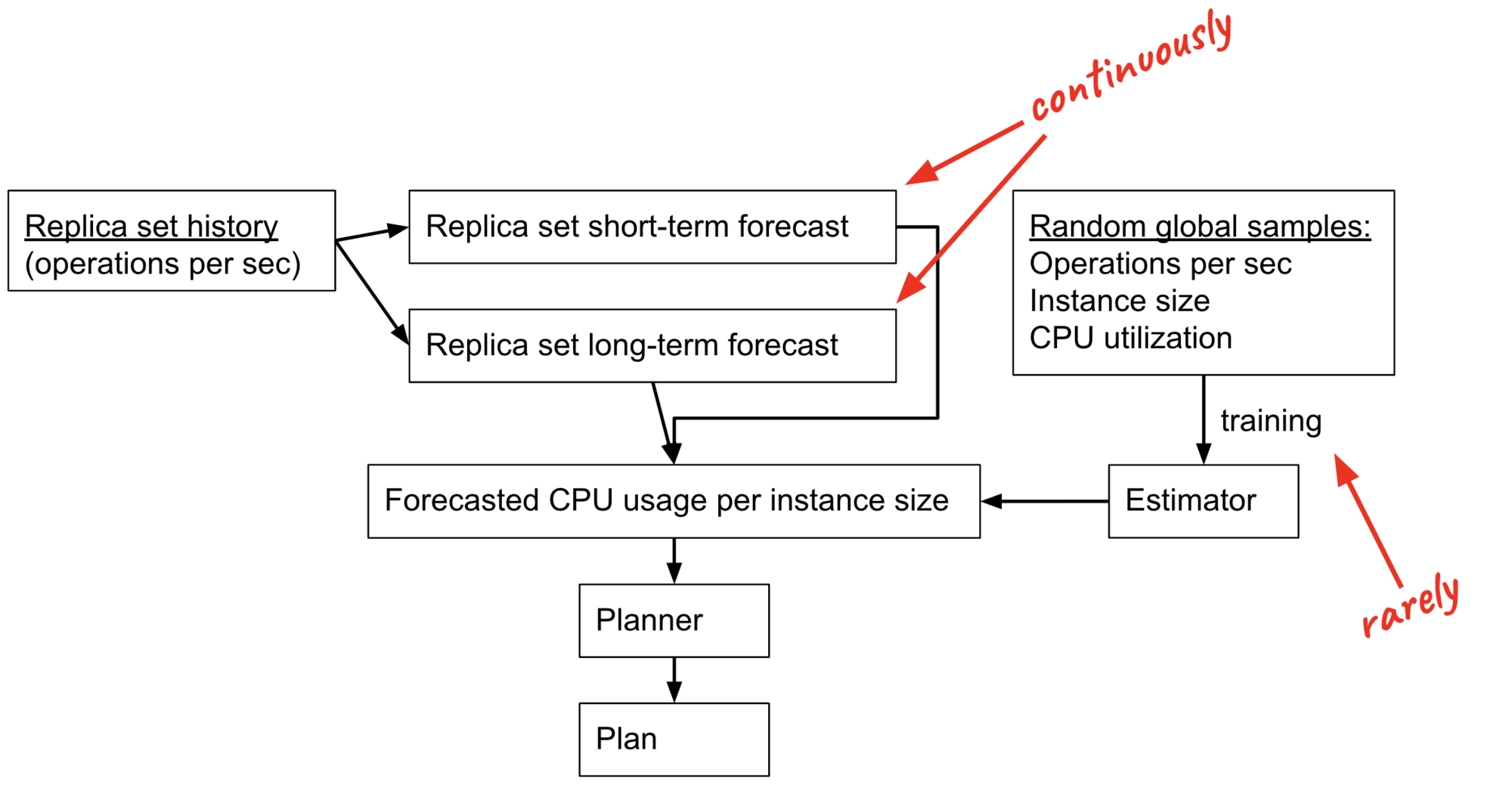
For each replica set, its history is an input to the Short-Term and Long-Term Forecasters. (I’ll explain why we have two Forecasters soon.) The Forecasters must be retrained every few minutes, as new samples arrive.
From the same data warehouse we sampled 25 million points in time from any replica set in Atlas. Each of these samples includes a count of operations per second (queries, inserts, updates, etc.), an instance size, and the CPU utilization at that moment. We used this to train the Estimator, which can predict the CPU utilization for any amount of customer demand and any instance size. This is a hard problem, since we can’t see our customers’ queries or their data, but we did our best. The Estimator must be retrained rarely, when there’s new hardware available, or a more efficient version of the MongoDB software. (Eventually we plan to train an Estimator for each MongoDB version.)
The Forecasters and Estimator cooperate to predict each replica set’s future CPU on any instance size available. E.g., they might predict that 20 minutes in the future, some replica set will use 90% CPU if it’s on M40 servers, and 60% CPU if it’s on more powerful M50 servers.
Predictive Scaling: Planner #
Let’s look at the Planner in more detail. Here’s a forecasted workload, it’s forecasted to rise and then fall.
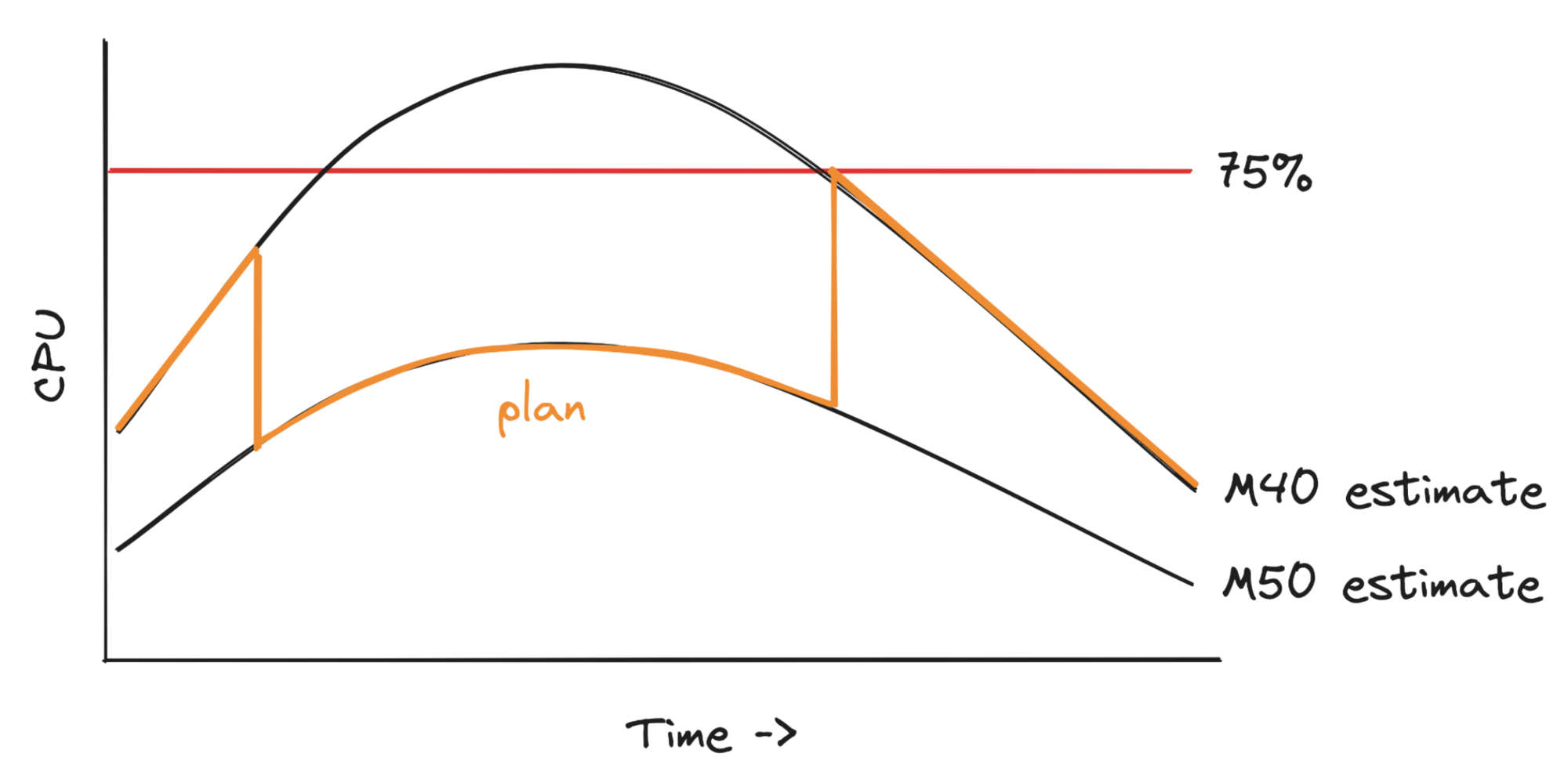
So the Planner’s plan is to use M40 servers until it would be overloaded, then switch to M50 during the peak, then switch back. Notice the replica set should start scaling up 15 minutes before the overload arrives, so the scale-up is complete in time to avoid overload. It starts scaling down as soon as the risk of overload has passed.
Predictive Scaling: Long-Term Forecaster #
Our goal is to forecast a customer’s CPU utilization, but we can’t just train a model based on recent fluctuations of CPU, because that would create a circular dependency: if we predict a CPU spike and scale accordingly, we eliminate the spike, invalidating the forecast. Instead we forecast metrics unaffected by scaling, which we call “customer-driven metrics”, e.g. queries per second, number of client connections, and scanned-objects rate. We assume these are independent of instance size or scaling actions. (Sometimes this is false; a saturated server exerts backpressure on the customer’s queries. But customer-driven metrics are normally exogenous.)
Our forecasting model, MSTL (multi-seasonal trend decomposition using LOESS), extracts components from the time series for each customer-driven metric for an individual replica set. It separates long-term trends (e.g., this replica set’s query load is steadily growing) and “seasonal” components (daily and weekly) while isolating residuals. We handle these residuals with a simple autoregressive model from the ARIMA family.

MSTL (multi-seasonal trend decomposition using LOESS)
By combining these components, we forecast each metric separately, creating a “Long-Term Forecaster” for each. Despite the name, the Long-Term Forecaster doesn’t project far into the future; it’s trained on several weeks of data to capture patterns, then predicts a few hours ahead.

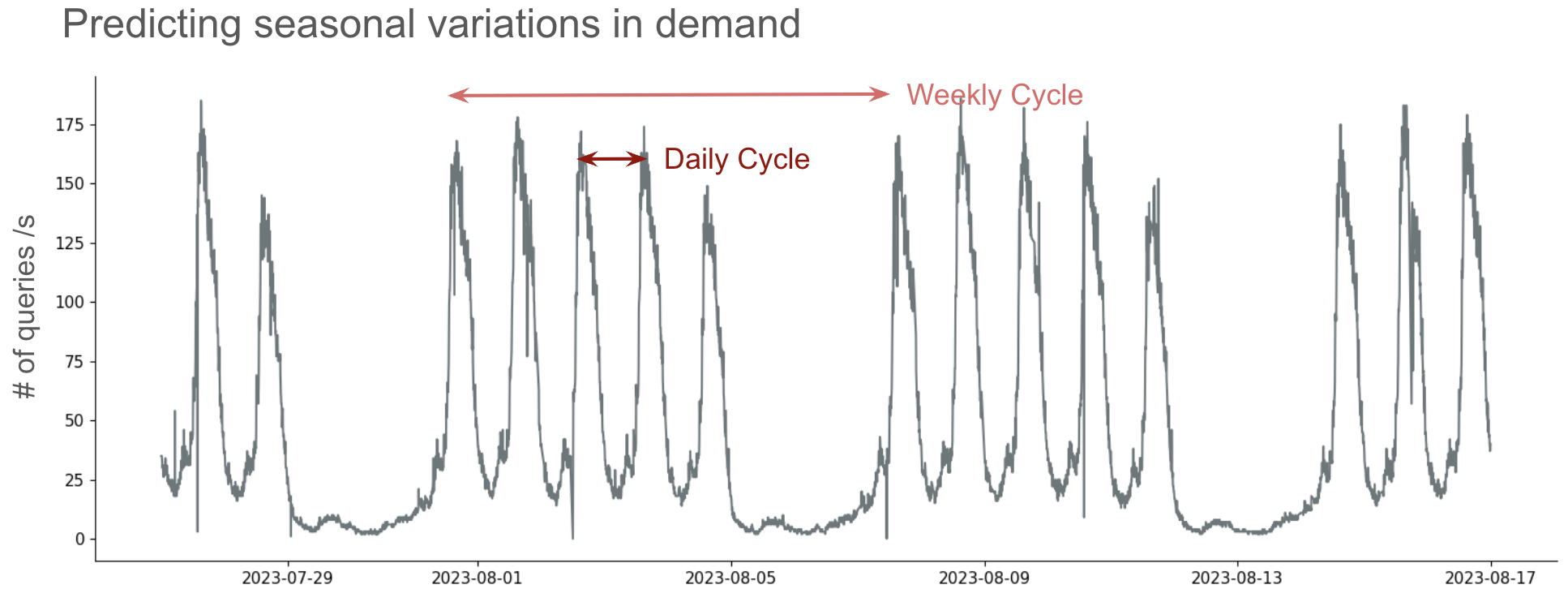
How often is demand seasonal?
Most Atlas replica sets have daily seasonality. About 25% have weekly seasonality. Generally if a replica set has weekly seasonality it also has daily seasonality. Hourly seasonality is rare, and anyway it isn’t helpful for planning a scaling operation that takes a quarter-hour. Replica sets with sufficient daily/weekly seasonality are predictable by the Long-Term Forecaster.

Example “long-term” forecast.
But only some replica sets have seasonality! For non-seasonal clusters, the Long-Term Forecaster’s prediction of customer-driven metrics is unusable.
| Seasonal Clusters | Non-seasonal Clusters | |
|---|---|---|
| Connections | 3% | 50% |
| Query Rate | 19% | 71% |
| Scanned objects Rate | 27% | 186% |
| ↑ unusable |
So we added a “self-censoring” mechanism to our prototype: the Long-Term Forecaster scores its own confidence based on its recent accuracy, and only trusts its prediction if its recent error has been small.
Predictive Scaling: Short-Term Forecaster #
What can we do when the Long-Term Forecaster isn’t trustworthy? We didn’t want to fall back to purely-reactive scaling; we can still do better than that. We prototyped a “Short-Term Forecaster”: this model uses only the last hour or two of data and does trend interpolation. We compared this to a naïve baseline Forecaster, which assumes the future will look like the last observation, and found that trend interpolation beats the baseline 68% of the time (29% reduction in error).

Approximation of local trends for near future forecast.
Predictive Scaling: Estimator #
The Forecasters predict customer demand, but we still need to know whether CPU utilization will be within the target range (50-75%). That’s the Estimator’s job. The Estimator takes the forecasted demand and an instance size (defined by CPU and memory), and outputs projected CPU. Using a regression model based on boosted decision trees trained on millions of samples, we’ve achieved fairly accurate results. For around 45% of clusters, our error rate is under 7%, allowing us to make precise scaling decisions. For another 42%, the model is somewhat less accurate but useful in extreme cases. We exclude the remaining 13% of clusters with higher error rates from predictive scaling.

Example of input and output of Estimator.
Predictive Scaling: Putting It All Together #
With both forecasts and CPU estimates, the Planner can choose the cheapest instance size that we guess can handle the next 15 minutes of customer demand without exceeding 75% CPU. Our experiment showed that this predictive scaler, compared to the reactive scaler in use during the test period, would’ve stayed closer to the CPU target and reduced over- and under-utilization. For the average replica set it saved 9 cents an hour. That translates to millions of dollars a year if the predictive scaler were enabled for all Atlas users.
| Predictive auto-scaler | Reactive auto-scaler | |
|---|---|---|
| Average distance from 75% CPU target | 18.6% | 32.1% |
| Average under-utilization | 18.3% | 28.3% |
| Average over-utilization | 0.4% | 3.8% |
What’s next? Matthieu and other MongoDB people are improving the Estimator’s accuracy by adding more customer-driven metrics, and estimating more hardware metrics: not just CPU, but also memory, and perhaps co-modeling CPU and memory to capture interactions between them. We want to investigate the minority of customers with bad estimates and ensure the Estimator works for them too. We’ll try building specialized Estimators for each cloud provider and each MongoDB version. MongoDB can’t see our customers’ data or queries, but we can gather statistics on query shapes—maybe we could use this to improve estimation.
I can’t tell you a release date. Par for a public blog post, but still disappointing, I know. In this case we honestly need more experiments before we can plan a release. A private beta for a few customers will come soon. Before we can unleash a complex algorithm on our customers’ replica sets we need a lot more confidence in its accuracy, and a lot of safeguards. We’ll always need the reactive auto-scaler to handle unexpected changes in demand. But I’m excited at the prospect of eventually saving a ton of money and electricity with precise and proactive auto-scaling.

Predictive and reactive auto-scalers, cooperating.
Further reading:
- This work was heavily inspired by Rebecca Taft’s PhD thesis
- Also interesting: Is Machine Learning Necessary for Cloud Resource Usage Forecasting?, ACM Symposium on Cloud Computing 2023.
- MongoDB Atlas.
- Cycling images from Public Domain Review.