Review: Automated Design of Agentic Systems
Automated Design of Agentic Systems, by Shengran Hu, Cong Lu, and Jeff Clune (UBC, Vector Institute), at ICLR 2025.
Clune has written a bunch of papers on evolving, self-improving systems. His AI Scientist paper made waves in 2024, maybe because it was a direct threat to the livelihoods of its readers.
In today’s paper, “Automated Design of Agentic Systems,” the authors ask: rather than hand-crafting agent architectures like Chain-of-Thought, Self-Refine, and LLM Debate, can we tell a meta-agent to invent them? The authors wrote a 100-line Python program that tells GPT-4 to write new, “interesting and novel” agents. This meta-agent writes little agent systems, which are a dozen lines or so of Python that calls GPT-3.5. The meta-agent evaluates the little agentic systems on a benchmark, and adds them to an ever-growing archive of previous attempts. The discovered systems are run with GPT-3.5 to keep costs down; even so a single run cost $300 to $500 in tokens in 2025. The claim is that the resulting systems beat state-of-the-art hand-designed systems on AI benchmarks (DROP, MGSM, and ARC), and transfer well across domains and models.
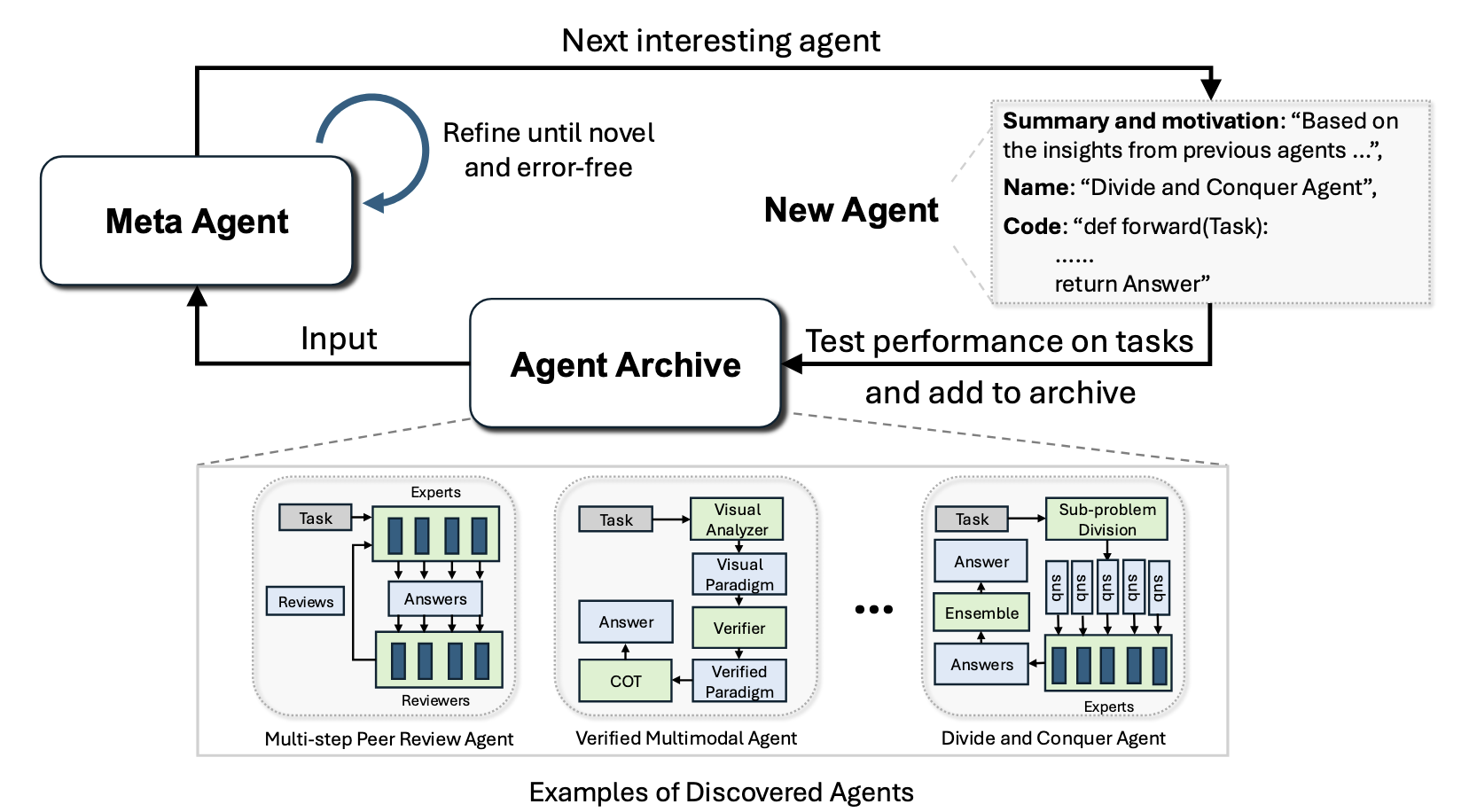
There’s no consensus among researchers about terminology for pieces of agentic systems. The paper defines its own usage: an “agent” is the same as an “agentic system”, a workflow that uses Foundation Models (FMs) like GPT-3.5 as modules to plan, call tools, and run multi-step processing. So each little agentic system discovered by the meta-agent is just “an agent,” even though internally it fires off many FM calls. I would personally call the internal FM calls “sub-agents”. But in this paper, the authors call them modules, experts, reviewers, critics, or roles (e.g. “Efficiency Expert,” “Readability Expert”).
The paper’s central design argument is that searching in code space is strictly more expressive than searching in the network or graph spaces used by predecessors like DyLAN and GPTSwarm. Those systems have a fixed vocabulary of nodes (an LLM call with a specific prompt, or a role-assigned agent) and optimize which nodes to include and how to wire them together. But in this paper, the meta agent can use Python’s full power: arbitrary control flow, new tool invocations, and so on. Because Python is Turing-complete, the paper argues, the code search space contains all possible networks or graphs. The authors also claim that discovered agents are more interpretable than DyLAN and GPTSwarm: they’re very short Python programs, not a tangle of edge weights. I buy that, but on the other hand, if you’re optimizing edge weights of a graph you can estimate an optimization gradient with simple math. If you’re telling a meta agent to try interesting and novel agent architectures, you can’t estimate the gradient: you rely on the meta-agent to guess what changes might improve its benchmark score.
Word-problem scores #
It seems to me that the authors chose weird benchmarks. I assume they faced the same problem most CS has: we want to use existing benchmarks because that’s “science,” even when the existing benchmarks are inappropriate.
The authors compare Meta Agent Search (their invention) to previous systems of the last few years: Chain-of-Thought, Self-Refine, LLM Debate, and so on. These systems compete on these benchmarks:
- MGSM (Multilingual Grade School Math) 250 grade-school math word problems, manually translated into ten languages, used to test multilingual chain-of-thought reasoning.
- DROP (Discrete Reasoning Over Paragraphs) Math word problems with more of an emphasis on reading comprehension than complex math. Each question requires discrete math reasoning (counting, addition, sorting, comparing) from a short paragraph.
- MMLU (Massive Multitask Language Understanding) A 57-subject multiple-choice exam spanning humanities, STEM, social sciences, and professional fields, meant to measure broad world knowledge and problem solving.
- GPQA (Graduate-Level Google-Proof Q&A) 448 graduate-level multiple-choice questions in biology, physics, and chemistry, written by domain PhDs to be “Google-proof”: hard even when the test-taker has unrestricted web access.
Multi Agent Search is significantly better than its competitors on the math tests (DROP and MGSM), but barely beats them on the science and multi-task tests. That’s predictable: the MMLU asks questions like, “The constellation … is a bright W-shaped constellation in the northern sky.” The agents are banned from searching the web, so if they don’t already know the answer is Cassiopeia, no fancy multi-expert architecture will help. Like I said, it’s a weird benchmark. I’d love to see this whole approach with Internet-connected agents, against more benchmarks that really exercise the architectures rather than the base model’s training data.
Grid puzzle scores #
ARC (Abstraction and Reasoning Corpus) is a set of visual grid puzzles where the system has to infer a transformation rule from a handful of input/output examples. It’s intended as a test of general fluid intelligence rather than learned knowledge. Here’s an ARC puzzle:
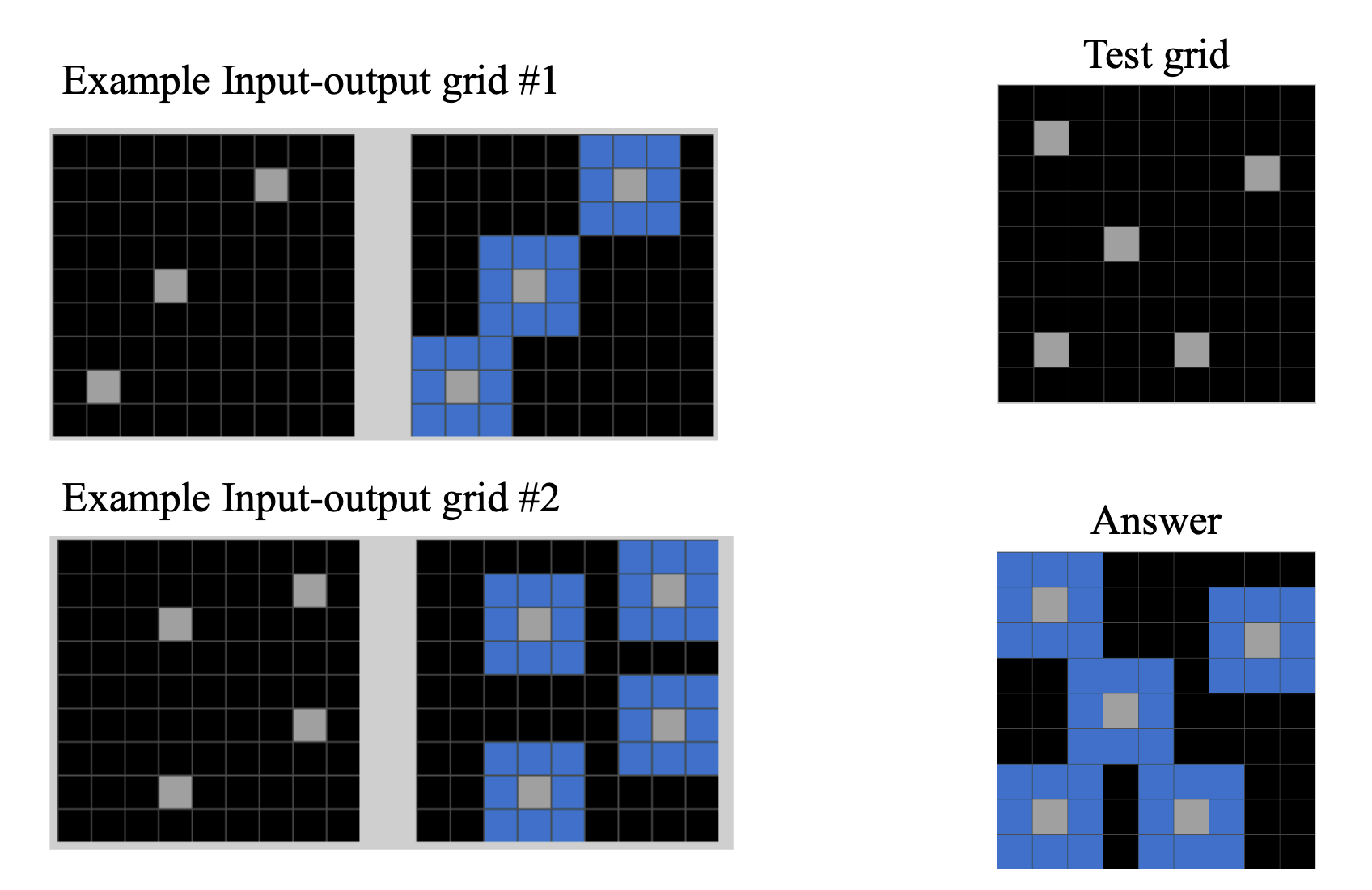
The agent sees the examples on the left. It sees the test on the upper right, and it wins a point by correctly guessing the answer on the lower right (which is hidden from it). It has to infer some general pattern, in this case “find all squares next to gray squares and color them blue.” Then it writes a Python program that applies that transformation to the test grid (upper right) and hopes to produce the correct output (lower right).
As the meta agent developed agents, it quickly beat its competitors and continued improving its score:
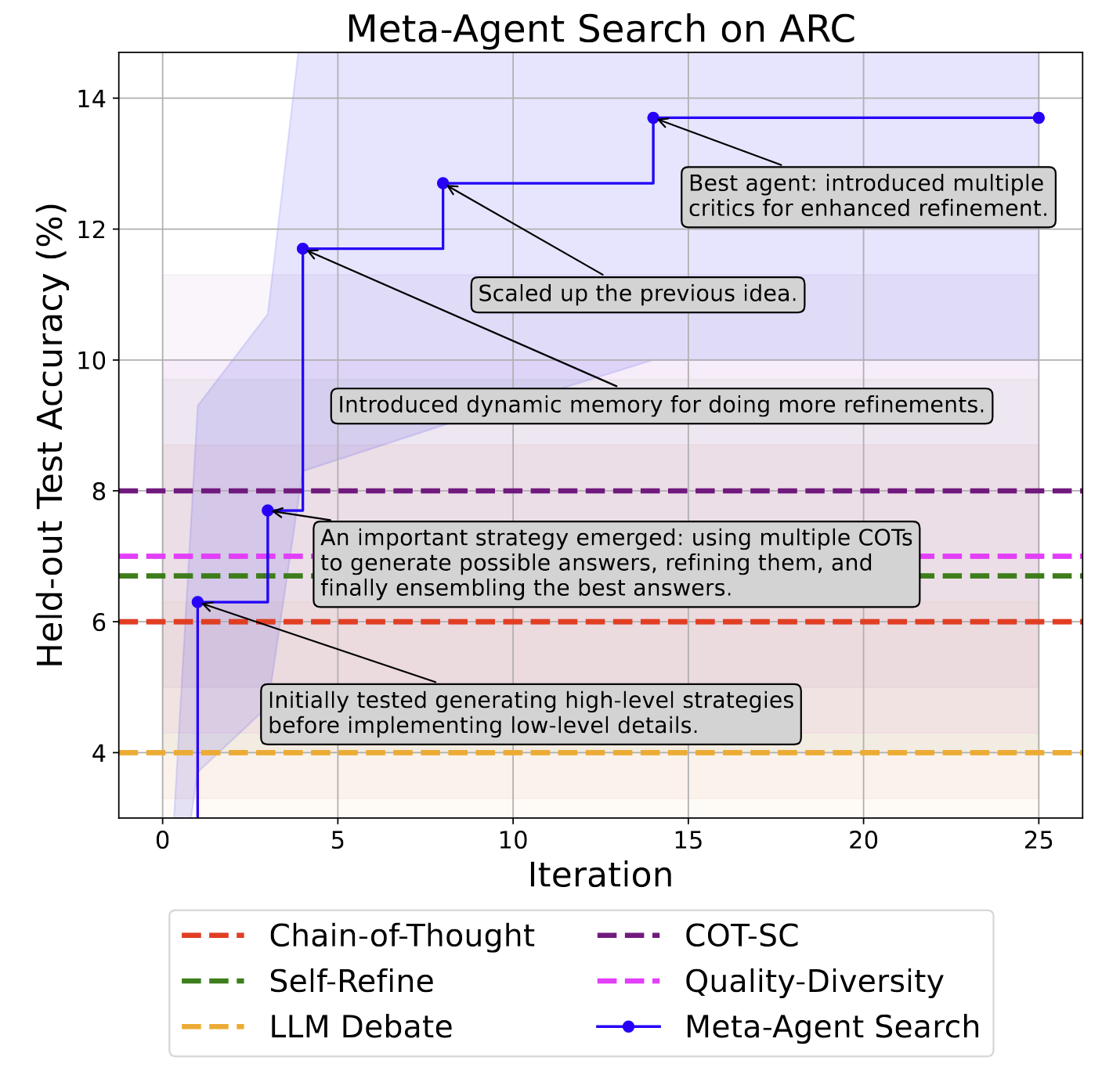
This is really cool! But the winning agent built by the meta agent has a weird architecture:
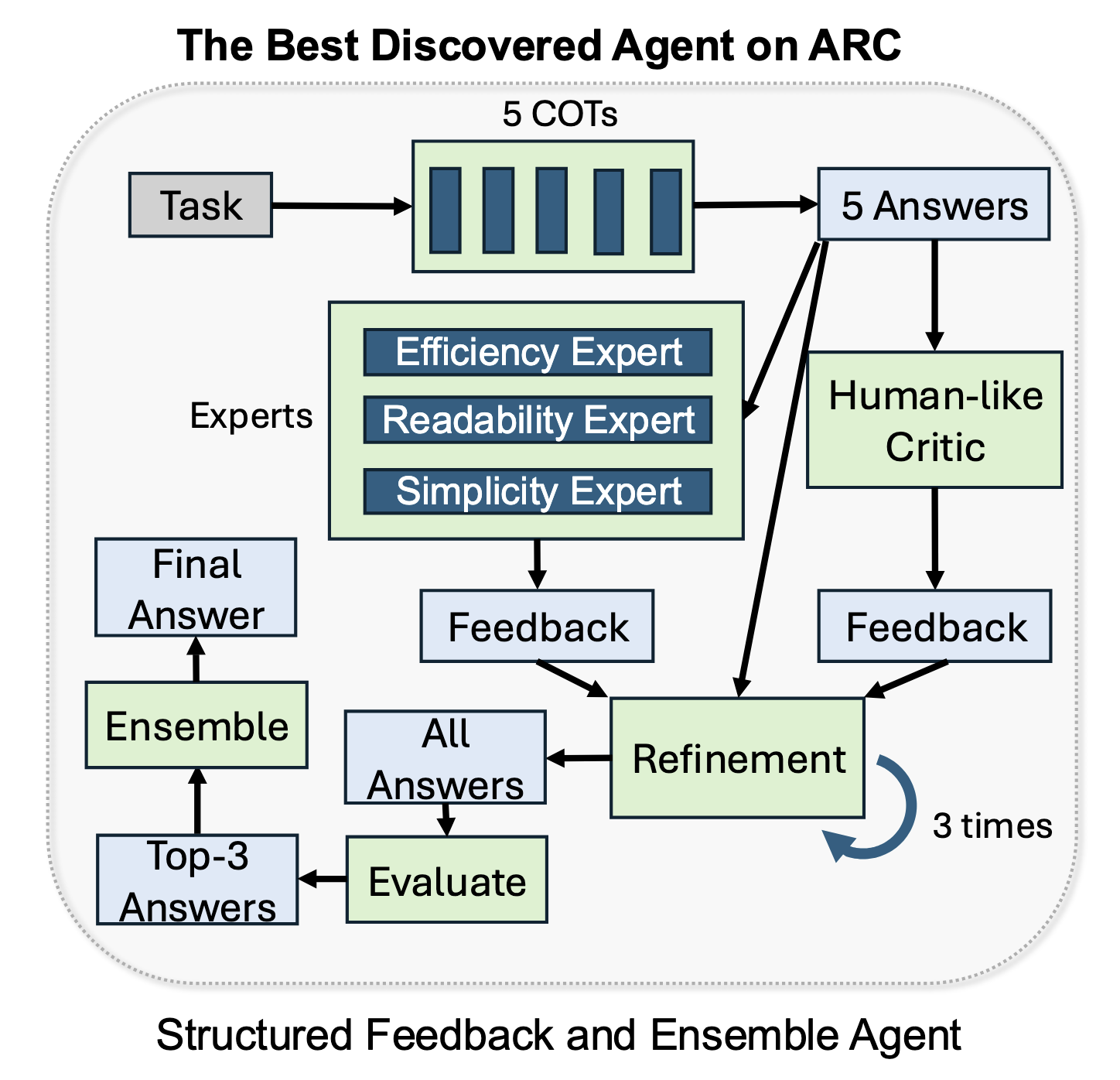
The agent is a committee. It uses chain-of-thought to generate 5 candidate Python programs. Then it tells GPT-3.5 to act in various roles (efficiency expert, readability expert, simplicity expert, “human-like critic”) to choose and refine one of those candidates.
But ARC doesn’t evaluate the program on its subjective code-quality measures, it only checks whether its output matches the correct answer. Efficiency and readability are irrelevant. So how are these “experts” improving the score? The paper doesn’t say, but I’d bet their opinions about efficiency or readability don’t matter. It’s possible the Simplicity Expert helps because a “simpler” solution generalizes from the few-shot examples instead of overfitting to specific grid positions. I’d like to see an ablation: remove or replace the experts one by one, and see whether the architecture’s complexity is load-bearing or decorative.
I also wonder why the meta agent came up with this architecture. I guess GPT-4 was trained to be a good code assistant, and when it was asked to “create a coding agent” it applied some of the best practices it was rewarded for. Maybe if it was asked, “Write shitty code and beat this test by any means necessary,” it would have made different choices. Would its best agent have scored higher on ARC then, or at least spent fewer tokens on debating the code’s beauty?
What Does It All Mean? #
It’s hilarious how human-shaped the discovered patterns are. The meta agent reinvented peer review, editorial boards, code review, and role-assigned committees. These are the structures we invented for teams of humans. Except the LLM “human-like critic” starts reviewing immediately instead of waiting to be pinged on Slack three times.
The deeper principle is that LLMs behave more like people than like conventional software: they’re better when they write their thoughts down as they go, they’re bad at arithmetic and should use a calculator, they’re more honest if you put them in a room and tell them to criticize each other. Meta Agent Search is an automated rediscovery of how humans cooperate to be less wrong. Its agents encode metacognitive tricks to avoid cognitive bias.
The next step, naturally, would be a meta meta agent, etc. Or else the meta agent could redesign itself, and initiate a hard takeoff. The authors defer this madness to “future research”.
Great bots make little bots to think of codes and write ’em,
And little bots have lesser bots, and so ad infinitum.
And the great bots themselves, in turn, have greater bots to go on;
While these again have greater still, and greater still, and so on.
