Review: Paxos Quorum Leases: Fast Reads Without Sacrificing Writes
Paxos Quorum Leases: Fast Reads Without Sacrificing Writes, by Iulian Moraru, David Andersen, and Michael Kaminsky, in SoCC 2014.
It’s about Paxos, but don’t be intimidated: this is an accessible paper about speeding up linearizable reads in geo-distributed groups of servers, supposedly without harming write performance too badly.
Table Of Contents
The Problem #
In a replicated system like Multi-Paxos, a client sends a write request w to the leader, which forwards it to the followers. When a majority of replicas (including the leader) acknowledges w, the leader “commits” the command (actually executes it on the leader’s local data) and tells the client and followers that the command is committed. The followers then execute the command on their local copy of the data to stay in sync.
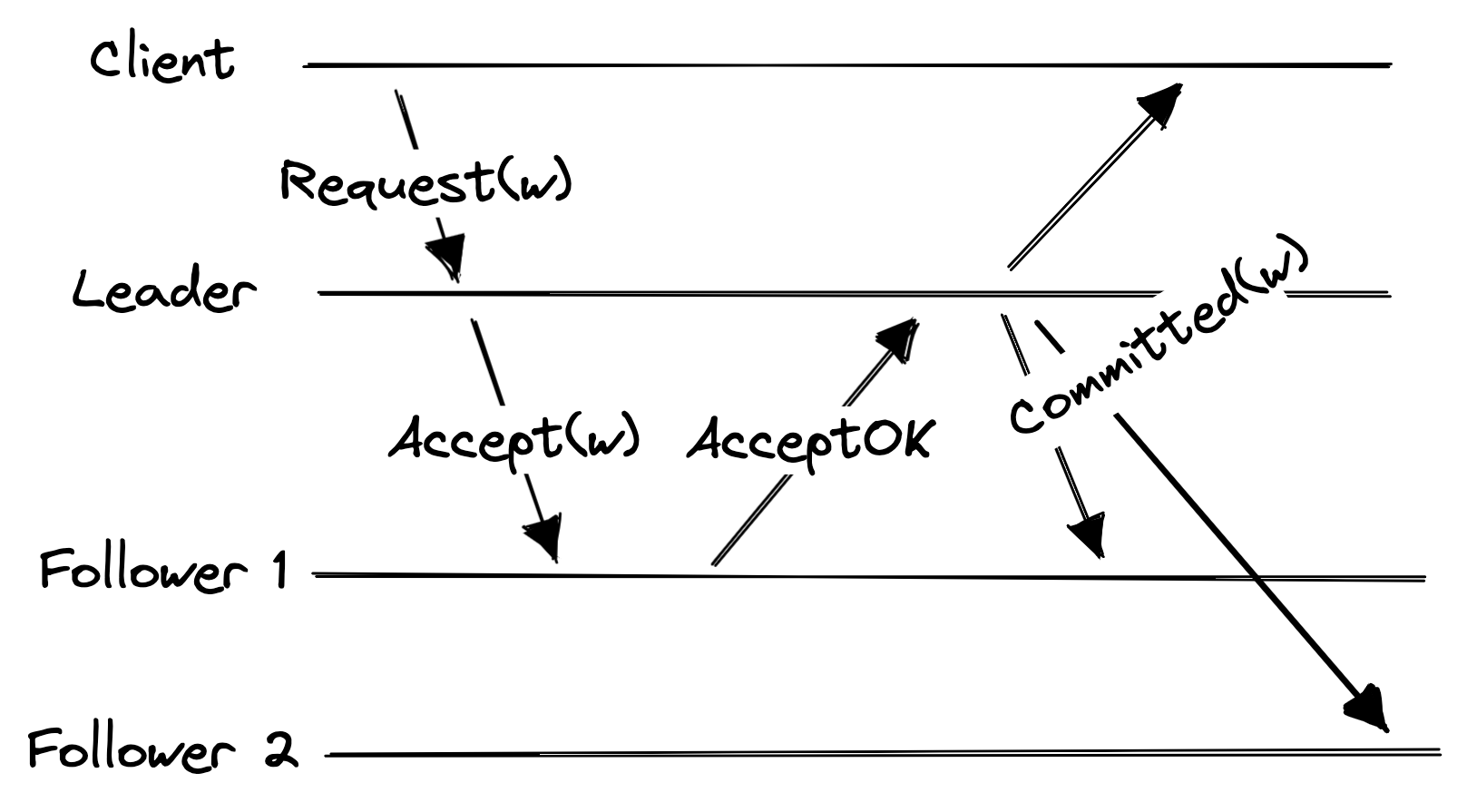
I adapted this from the authors' Figure 1.
A client reading the data might want “consistency”, which in this case means strict serializability. Strict serializability implies linearizability, which implies “no stale reads”: if a write operation w has completed before a read operation r begins, then r must see w’s effects; it must not see some earlier version of the data.
When the client queries the leader, the leader can provide consistent reads without extra latency, by holding a read lease: the followers promise not to become leaders for a period of time, which is constantly renewed while the leader is up, so the leader knows it’s the only leader and its local version of the data is the most up-to-date. (The leader also needs locks or whatever to ensure consistency despite its internal concurrency; we’re ignoring that and focusing on the distributed algorithm.)
But in a geo-replicated system the client might be distant from the leader, and want to query a nearby follower instead. There are some simple options:
- The follower replies immediately. This is quick but inconsistent: w could have completed on the leader, but the follower doesn’t know it yet, so the client sees stale data.
- The leader waits for all followers to acknowledge w, before the leader acknowledges w to the client. Thus follower reads are consistent: any read that starts after the leader acknowledges w will see w’s effects. This adds write latency, and risks unavailability if any follower dies.
- The leader waits for a majority of followers to acknowledge w, before the leader acknowledges w to the client, and every read checks a majority for the latest version of the data. This increases latency for reads and writes. (See Flexible Paxos for a generalization discovered after this paper.)
Update, later the same day: Murat Demirbas and Aleksey Charapko point out that option 3 isn’t in the paper. That’s true, I was just adding my own idea for a third option, and in fact I got it wrong. I’ll have to read their Paxos Quorum Reads paper next to educate myself.
Anyway, the “Paxos Quorum Leases” authors mention options 1 and 2, and they’re dissatisfied with both.
In this paper, we argue that there is an overlooked alternative that is a more natural fit to the structure of Paxos: quorum leases. In this model, a lease for each object in the system could be granted to different subsets of nodes. The size and composition of these subsets is selected either based upon how frequently each replica reads the objects in question (for best read performance) or based upon their proximity to the leader (to improve read performance without slowing write performance).

The Algorithm #
In this paper, a “lease” is the right to serve consistent reads on some subset of the data. There could be as many leases as distinct sets of data, though too many leases would create a lot of overhead. A lease is granted to a set of nodes for a period of time, which is constantly renewed. The lease-granters must be a majority of nodes, to prevent conflicting grants. The lease-holders could be any number of nodes.
Whenever the leader modifies some data, it promises to wait for acknowledgment from that data’s lease-holders before it acknowledges the write to the client. Since, in Paxos, the leader must wait for majority-acknowledgment for all writes anyway, it’s natural for each lease’s holders to be some majority.
You can see how this guarantees consistent reads. Say a client sends the leader a write operation w which modifies some chunk of data x. The leader waits for acknowledgment from x’s lease-holders before acknowledging the write to the client. If any client then reads x from one of the lease-holding followers, it will see w’s effects.
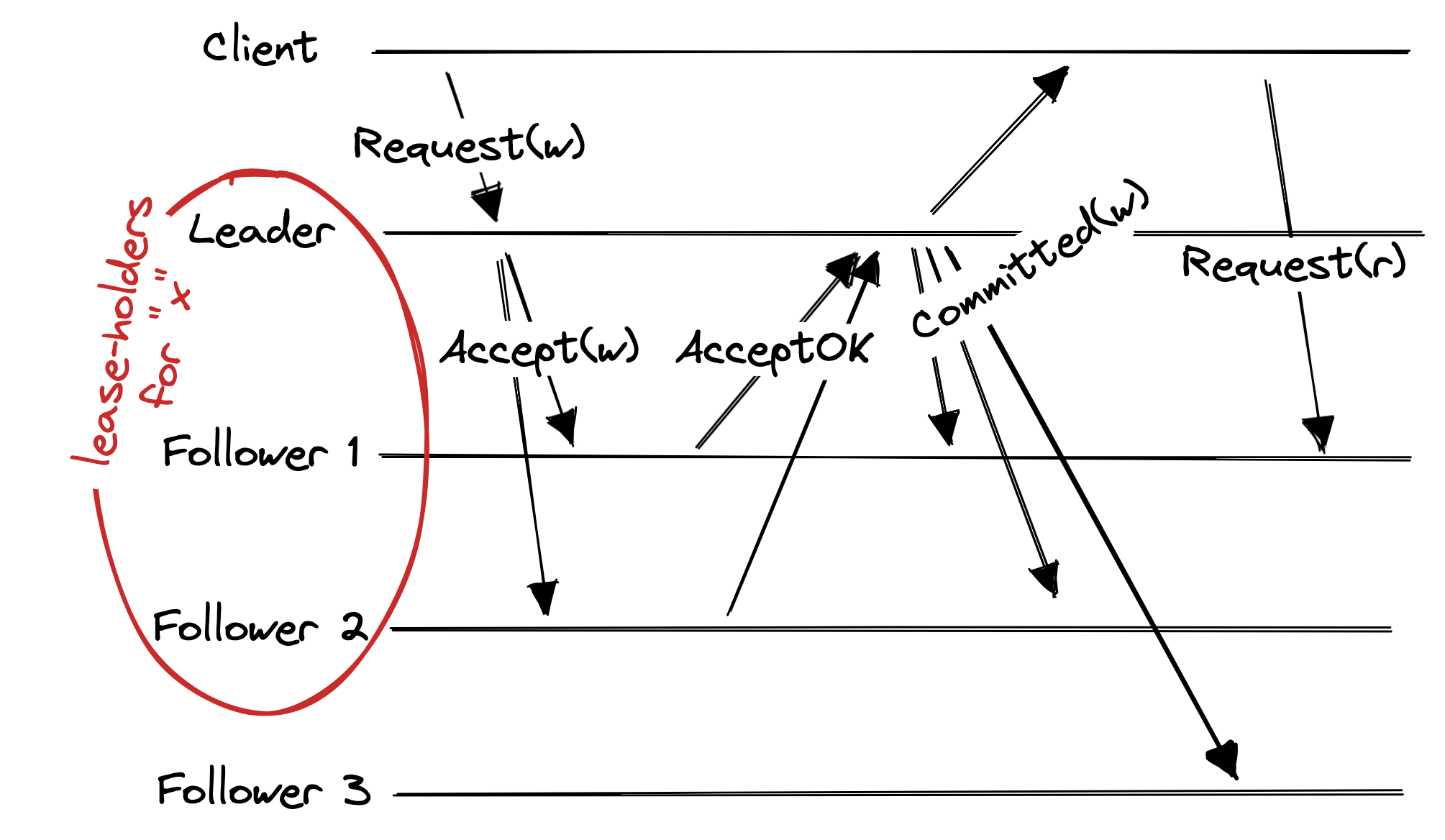
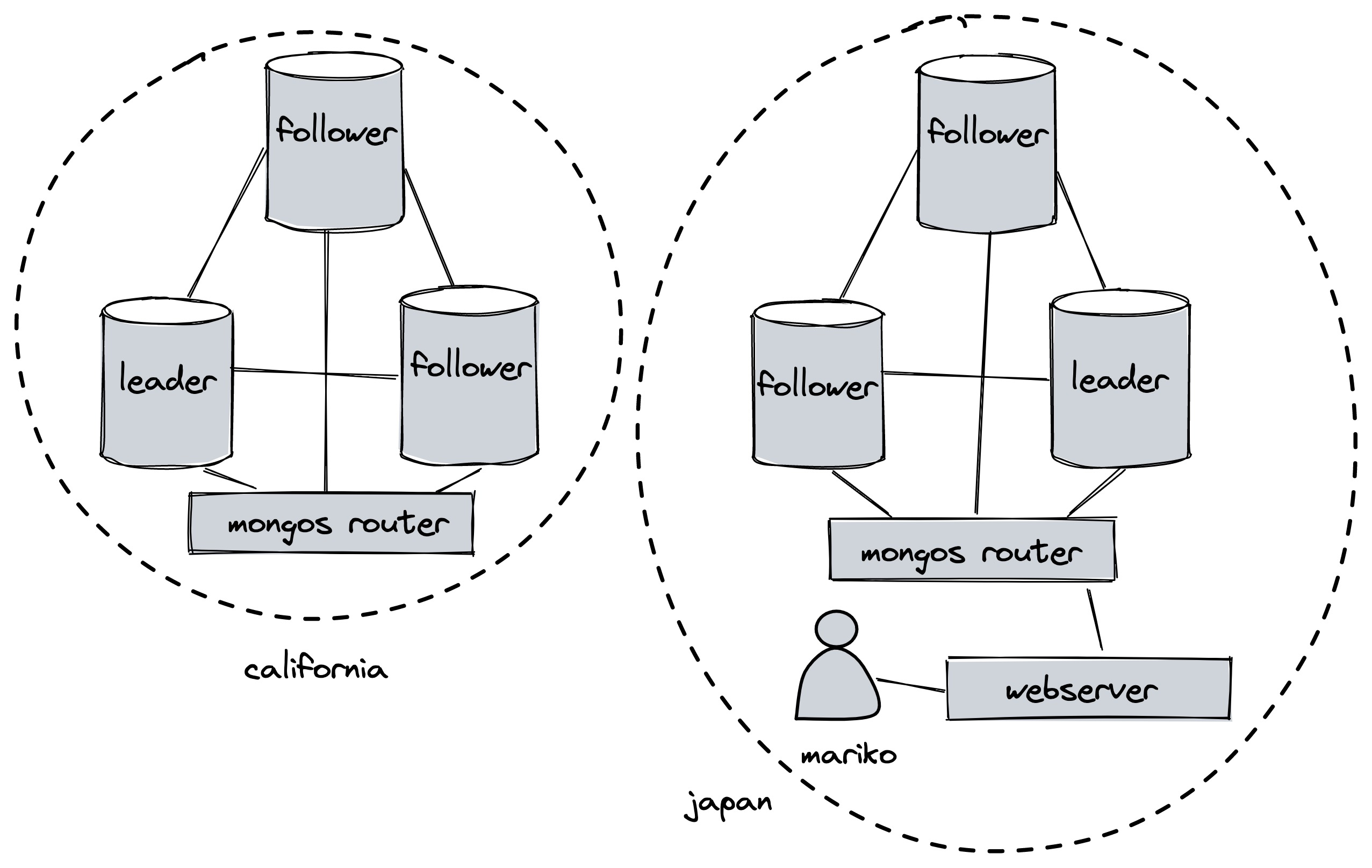
Here’s an example use-case (mine, not the authors’). Imagine a social network whose data is stored in one big geo-distributed Paxos group. The leader node is in California, perhaps, and a user named Mariko in Japan wants to log in. She connects to a webserver in Japan and sends her password hash.
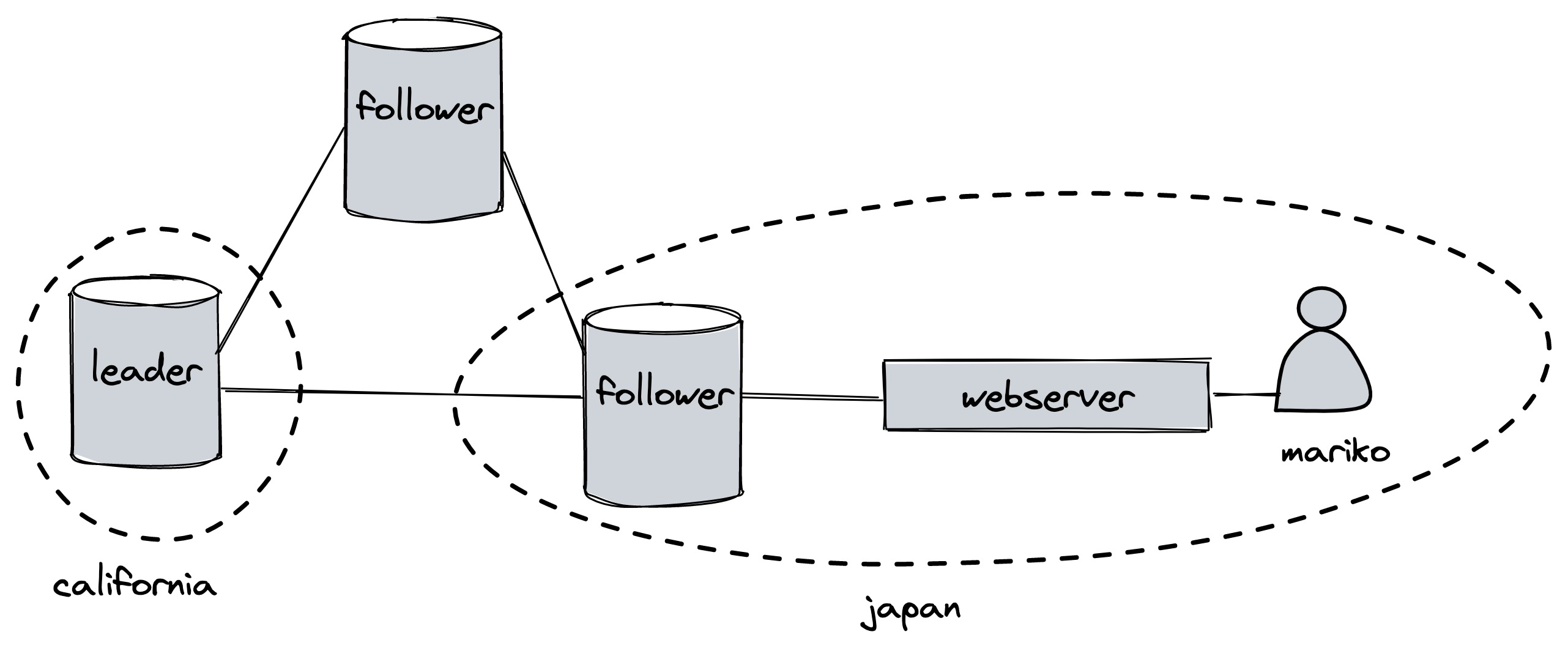
The Japanese webserver must check her password hash against the latest hash stored in the Paxos group; stale reads aren’t okay, because a password change must take effect instantly. Therefore the webserver needs a linearizable read. In regular Paxos, either the webserver would have to read from the leader in California, or else every password change would require acknowledgment from all nodes. But with quorum leases, some Paxos nodes in Japan could be granted read leases on Japanese users’ password hashes. So password changes for Japanese users would require acknowledgment from a quorum of Japanese Paxos nodes. The Japanese webserver checks Mariko’s hash against the one stored in a Japanese Paxos node with much lower latency, without compromising security.
Their Evaluation #
The authors made a prototype geo-replicated Paxos implementation and aimed a YCSB workload at it, using various ratios of reads to writes, and either a uniform or heavily skewed access pattern. When skewed, nodes in different regions had different hot keys. They implemented various styles of read leases and compared them to quorum leases.
In the authors’ opinion, quorum leases occupy a sweet spot that balances write latency and read latency. They claim that their quorum lease prototype serves 80% of reads from the nearest node, indicating that leases are granted efficiently to the nodes in the correct regions. Somehow, the authors say that “over 70% of updates have the minimum latency achievable by a geo-distributed Multi-Paxos system, matching that provided by the single leader lease”. In other words, write-acknowledgment from a specific quorum is usually as fast as write-acknowledgment from the fastest quorum. This surprises me, and see my concerns below.

My Evaluation #
If you thought regular Paxos was complicated, just wait 'til you add quorum leases. As the authors admit:
Despite the intuitiveness of this approach, implementing quorum leases is nontrivial. Compared to approaches in which the set of nodes with the lease is fixed—either a single master or all replicas—an implementation of quorum leases must be able to consistently determine which objects belong to which lease quorum, automatically determine appropriate lease durations, and efficiently refresh the leases in a way that balances overhead, a high hit rate on leased objects, and rapid lease expiration in the event of a node or network failure.
Let’s say you’ve implemented everything correctly. Now there are exciting new failure modes! In regular Paxos, if a majority of nodes is up, writes succeed. But with quorum leases, if any node goes down, writes fail to any data to which that node holds a lease. The system can recover, but not until the previous leases expire (on the order of 10 seconds).
Even when all nodes are up, I’m concerned about tail latency for writes. The authors’ well-tuned prototype usually executes writes as fast as regular Paxos would, but the tail latency is much worse. And real life is less predictable than a prototype: if just one lease-holder is slow, or far from the leader, write latencies would spike for all the data in its leases. Regular Paxos isn’t as vulnerable to a single-node incident.
Despite my concerns, I enjoyed reading this paper and I recognize that it’s a valuable contribution. Quorum leases are a clever idea; they extend a pseudopod of the Paxos amoeba into a new area of the problem space. The authors have tackled the complexity, and their prototype performs surprisingly well. In cases like my login example above, it could be worthwhile to assign quorum leases for some data that has the appropriate access patterns, like passwords, at the risk of write latency or unavailability—then use conventional Paxos for the rest of the data.
Should MongoDB Implement This? #
Whenever I read a paper I ask, “Should we implement this in MongoDB?” So let’s restate the problem the authors want to solve: some objects are frequently read from certain regions, we want linearizable reads, and there’s just one leader. So, quorum leases let followers in some regions serve local linearizable reads on some objects.
But MongoDB doesn’t have just one leader: we have sharding. Each shard is a replica set with its own leader. In my login example, we could use tags to place user data in the proper region. Each shard’s leader could serve linearizable reads to nearby clients.
Linearizable reads in MongoDB have the same latency as a majority-acknowledged write, so they’re slower than the single-node local reads of Paxos quorum leases, but we still avoid cross-region read latency. Quorum leases permit read-scaling by spreading reads across some followers, unlike linearizable reads from the leader with MongoDB. But MongoDB’s sharding also scales writes and avoids cross-region write latency, so it might be a better sweet spot for many applications.
| MongoDB tag-aware sharding | Paxos quorum leases |
|---|---|
| Linearizable reads from leader, as slow as majority write |
Local reads from some followers |
| Within-region writes | Cross-region writes |
| Write scaling | Read scaling |
Tag-aware sharding seems to cover most use cases well enough or better than quorum leases. For quorum leases to still be necessary, you’d have to require linearizable reads from followers (not just the leader), or linearizable reads that are faster than a majority-acknowledged write, or fast reads in multiple regions for the same data. Historically, people who need fast geo-distributed reads are willing to give up some consistency for that, and they don’t need to settle for eventual consistency: I think MongoDB’s causal consistency is a reasonably strong and intuitive consistency level that would solve this problem without as many drawbacks as quorum leases.
Images from The Principles of Light and Color, Edwin D. Babbit 1878.