Can We Rely On Timers For Distributed Algorithms?

Distributed systems people are suspicious of timers. Whenever we discuss an algorithm that requires two servers to measure the same duration, the first question is always, “Can we rely on timers?” I think the answer is “yes”, as long as you add a safety margin a little over 1/500th.
Table Of Contents
Example: Leader Leases Rely on Timers #
Leader-based consensus protocols like Raft try to elect one leader at a time, but it’s possible to have multiple leaders for a short period. (In theory, in a Raft group of 2f+1 servers, as many as f can be leaders at once!) In this situation, you risk violating read-your-writes:
- A client updates some data on the current (highest-term) leader.
- That leader majority-replicates the change and acknowledges it to the client.
- The same client reads stale data from an old leader that hasn’t stepped down.
A Raft leader must always suspect that it’s been deposed, so it acts paranoid: for each query, it checks with a majority to confirm it’s still in charge (Raft paper §8). This guarantees read-your-writes at a high cost in communication latency.
A leader lease guarantees a single leader, but it relies on timers. In Diego Ongaro’s thesis, he proposes a simple lease mechanism for Raft: The leader starts a timer at time t, and sends heartbeat messages to all its followers. Once a majority has responded, the leader knows they won’t vote for another leader until t + election timeout * ε, where ε is the maximum rate of clock drift. Here’s Figure 6.3 from Ongaro’s thesis:
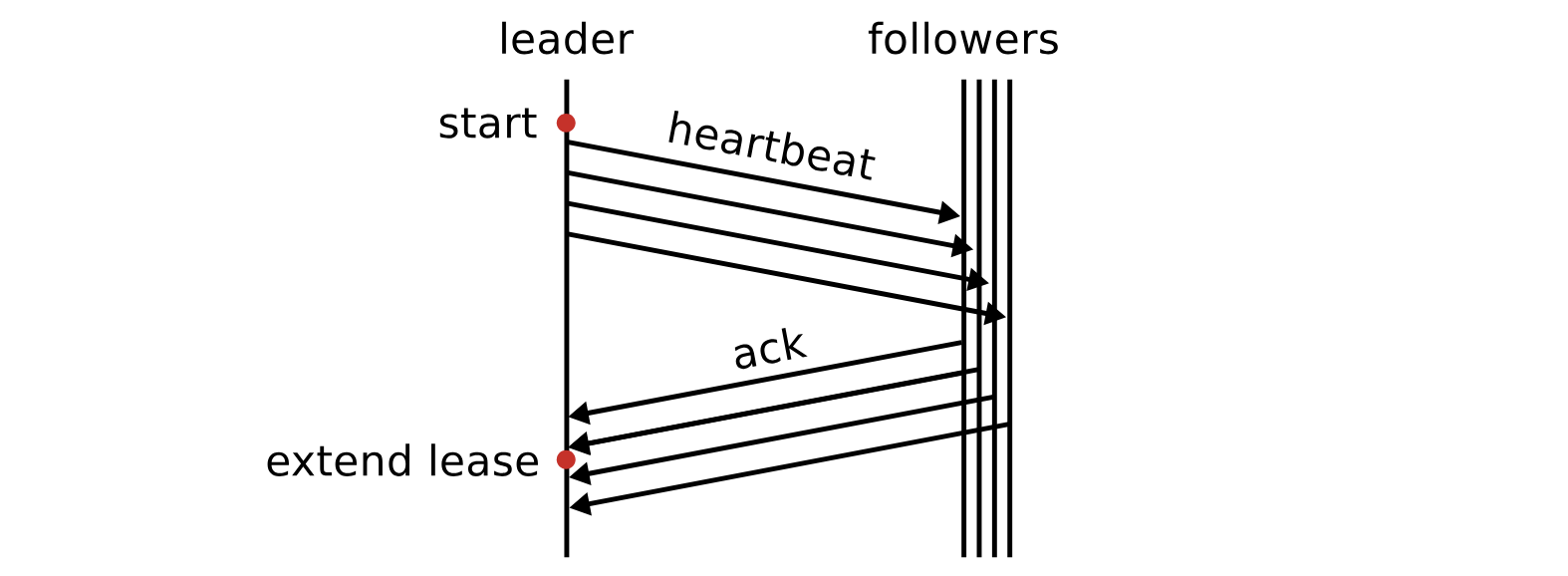
At MongoDB we made a more sophisticated lease algorithm that improves availability. Stay tuned for our research paper. But just like Ongaro’s, our algorithm depends on timers.
Why We Distrust Timers #
In the classic asynchronous system model, servers have no clocks and delays are unbounded. FLP impossibility says that in this model, no consensus algorithm is guaranteed to make progress. I believe this means no protocol can both 1) always eventually elect one leader and 2) prevent multiple concurrent leaders. This is what makes Raft leaders paranoid.
But if we relax the model slightly—allowing bounded timer inaccuracy—we can design more efficient protocols. In the timed asynchronous system model, servers use timers with bounded drift. This is, as I’ll argue below, a more realistic model, and it enables leader leases: a majority promises not to elect another leader for a duration. The leaseholder can serve reads without checking with peers.
At MongoDB Distributed Systems Research Group, we’re developing lease protocols for Raft and MongoDB. So I spent a few days researching this question: how reliable are timers?
Timer uncertainty #
With leader leases, the leader starts a timer for some duration d, and sends a message to its followers telling them to start timers for the same duration. Leases guarantee consistency so long as the leader believes its timer expires before any of its followers believe theirs do. I formulated this as the Timer Rule:
If server S0 starts a timer t0,
then sends a message to server S1,
which receives the message and starts a timer t1,
and S1 thinks t1 is ≥ d * ε old,
then S0 thinks t0 is ≥ d old.
We should make the safety margin ε large enough to guarantee this, but not unnecessarily large (which would hurt availability). Here are some sources of uncertainty:
Clock frequency error, a.k.a. “drift” #
Any server’s timer depends on a quartz oscillator (“XO”) on its motherboard, even if the server is a VM. All XOs are manufactured with some inaccuracy, and their speed is affected by age and temperature. XOs slow down if they’re too cold or too hot! Cloud providers control temperature fairly well in their data centers and they swap out components periodically, but not all servers are so well cared for.
NTP clients (ntpd or the more modern chronyd) measure oscillator drift over time (even across reboots) and compensate for it, disciplining the oscillator to near-perfection. In the last couple years, cloud providers have achieved clock synchronization within tens of microseconds, implying minuscule clock drift. However, for maximum safety let’s assume that NTP isn’t functioning at all. The servers’ timers are undisciplined and freely drifting.
It’s weirdly hard to find the model numbers for XOs commonly used in servers, but I think I found some examples (1, 2, 3). They usually advertise a maximum drift of ±50 ppm (parts per million) over a vast range of operating temperatures. (See this formula for the accuracy of XOs in general.) This matches the 50 ppm value that the AWS ClockBound engineers consider worst-case.

Clock slewing #
When ntpd or chronyd make routine clock adjustments, they slew it gradually to the correct time instead of stepping it discontinuously. The max slew rate for ntpd is 500 ppm hardcoded, for chronyd it’s 1000 ppm configurable.
Every few years the authorities announce a leap second to account for recent unpredictable changes in the earth’s rotation. It is announced 6 months ahead. Leap seconds will probably be canceled starting in 2035, in favor of a leap hour every few thousand years. If there are any leap seconds before 2035, different time providers may unfortunately implement them differently. AWS and GCP are likely to slew the clock for 24 hours (a 7 ppm slew rate) and Azure may ignore the leap second, introducing a 7 ppm discrepancy between timers in Azure and non-Azure during the 24 hours. But we can ignore leap seconds; we only care about the max slew rate, regardless of the reason for slewing.
Bottom line: the max slew rate is 1000 ppm.
VM interruptions #
Hypervisors have paravirtual clocks: the VM’s clock is a passthrough to the host clock, so when the VM wakes from a pause its clock is still up to date. AWS and GCP use the KVM hypervisor, which has kvm-clock. Azure uses Hyper-V, which has VMICTimeSync. Xen is going out of style, but it has something poorly documented called pvclock. If a VM pauses and resumes, its paravirtual clock won’t be affected. If it’s live-migrated to a different physical host, then presumably the accuracy of its timers across the migration depends on the clock synchronization between the source host and target host. Major cloud providers now sync their clocks to within a millisecond, usually much less.
Martin Kleppmann warns about checking a timer and then acting upon the result: your VM could be paused indefinitely between the check and the action. But his article is about mutual exclusion with a lease, and we’re just trying to guarantee read-your-writes. For us, the server only needs to be a leaseholder sometime between receiving a request and replying.
So what’s ε? #
Ideally, clock slewing cancels out frequency error to approximately zero. After all, the NTP client slews the clock in order to get it back in sync. But let’s pessimistically assume that clock slewing adds to frequency error. The sum of the errors above is 50 ppm (max frequency error) + 1000 ppm (chronyd’s max slew rate) = 1050 ppm. If two servers’ clocks are drifting apart as fast as possible, that’s 2100 ppm, or a little over 1/500th. So if we set ε = 1.0021, we’ll definitely obey the Timer Rule above. For example, if election timeout is 5 seconds (MongoDB’s default in Atlas), this means waiting an extra 11 ms to be sure.
How important is ε? #
We could probably get away with ignoring drift, and set ε = 1, and still never violate the Timer Rule. Recall the scenario I care about: S0 starts a timer and sends a message to S1, which starts its own timer. S1’s timer mustn’t expire before S0’s. There’s some builtin safety already, because S1’s timer will start after S0’s. The delay depends on network latency and processing time on each server; it will probably be much larger than timer inaccuracy.
If we rely on leases for consistency, then even if S1 thinks its timer expires too soon, it’s still hard to observe a consistency violation. There’s only a short time while S0 thinks it still has a lease, but S1 thinks S0’s lease expired. During this window all the following must happen:
- S1 runs for election, and wins.
- S1 receives a write command, majority-replicates it, and acknowledges it to the client.
- S0 receives a query for some data that was just overwritten on S1.
- S0, thinking it still has a lease, runs the query on stale data and replies.
This sequence would violate read-your-writes. It’s hard to imagine all those events in the milliseconds or microseconds between the two timers’ expirations. It seems more likely to me that the Timer Rule is violated, not because ε is a smidgen too small, but because some misconfiguration makes a timer wildly inaccurate.
In MongoDB’s version of Raft, the violation is even less likely, because the MongoClient will know that S0 has been deposed. You have to use multiple MongoClients, or restart your client application, to lose this information and observe the consistency violation. See my causal consistency article for a technique to handle this case.
In summary, a user would have to be very unlucky to observe a consistency violation with leases: they’d need a Raft group with two leaders due to a network partition, but the user can talk to both sides. They’d have to use two clients (to disable MongoClient’s deposed leader check), write to the new leader, and quickly read the overwritten data from the old leader. The old leader would have to somehow fail to step down, while the new leader won election surprisingly quickly. And finally, the lease mechanism would have to fail because clock frequency error was worse than ε.
In meta-summary, I think distributed systems implementors should rely on timers more. Whenever I discuss leases with engineers, the first question is, “Can we rely on timers?” It’s good to ask this question, but sometimes we have to take “yes” for an answer.

Images: Wellcome Collection.