How To Use MongoDB Causal Consistency
MongoDB implemented a consistency level called causal consistency in 2017 (version 3.6). It’s quite a handy consistency level, strong enough for most applications and still performant. I helped design the API for causal consistency, but when we released it I dropped the ball and didn’t publicize or document it well. MongoDB’s causal consistency didn’t get the fame it deserved in 2017; I’ll try to rectify that now.

MongoDB implements a Raft-like consensus protocol. Most people deploy MongoDB as a three-server replica set, with one primary and two secondaries. Only the primary executes writes, which are replicated by secondaries with a small delay. You can read from the primary or the secondaries. Your application talks to the servers via an instance of the MongoClient class.
The Problem With Secondary Reads #

Liam
Let’s start with the classic example: you’ve implemented a social media site, with MongoDB as your database. Some influencer named Liam posts something witty to your site, then clicks on his profile to admire his wittiness. But Liam doesn’t see his latest post! He desperately refreshes, and phew: soon his new post appears. What happened?
The problem is that you have tried to decrease load on the primary by reading posts from secondaries. For example, in Python:
client = MongoClient("mongodb://srv1,srv2,srv3/?replicaSet=rs")
# Configure this collection object to read from secondaries.
posts_collection = client.db.get_collection(
"posts",
read_preference=ReadPreference.SECONDARY)
# The insert message goes to the primary
# and awaits majority replication.
posts_collection.insert_one(
{"user_id": "Liam", "contents": "I'm very witty"})
# Read from secondary, due to "read_preference" above.
user_posts = list(posts_collection.find({"user_id": "Liam}))
MongoClient sends the insert command to the primary, which by default awaits acknowledgment from a majority of servers: in a three-server replica set, a majority is the primary plus one secondary. But then, MongoClient sends the find command to a random secondary—perhaps the other secondary, which may not have replicated the new post yet.

Reading from secondaries is unpredictable. You can’t reliably read your writes. You can’t do monotonic reads either: as you execute a series of reads on secondaries, you’ll use secondaries with different amounts of replication lag, so your data will seem to randomly jump back and forth in time. Secondary reads give you only the weakest guarantee, eventual consistency.
Causal Consistency #
We want you to be able to read from secondaries with reasonable consistency, so in MongoDB 3.6 we introduced causal consistency, which guarantees read-your-writes and monotonic reads. As we wrote in Implementation of Cluster-wide Logical Clock and Causal Consistency in MongoDB,
Causal Consistency is defined as a model that preserves a partial order of events in a distributed system. If an event A causes another event B, causal consistency provides an assurance that every other process in the system observes the event A before observing event B. Causal order is transitive: if A causes B and B causes C then A causes C. Non causally ordered events are concurrent.
You enable causal consistency with a session:
# Note read_concern, which isn't in the code above.
posts_collection = client.db.get_collection(
"posts",
read_preference=ReadPreference.SECONDARY,
read_concern=ReadConcern("majority"))
# start_session() has causal_consistency=True by default.
with client.start_session() as s:
posts_collection.insert_one(
{"user_id": "Liam", "contents": "I'm very witty"}, session=s)
# Read your previous write, even from a secondary!
user_posts = list(posts_collection.find(
{"user_id": "Liam}, session=s))
# This query returns data at least as new as the previous
# query, even if it chooses a different secondary.
n = posts_collection.count_documents({}, session=s)
You have to pass the session parameter with every command. This is too easy to forget—I forgot it when I first wrote this example!
In a causally consistent session, you’ll read your writes and get monotonic reads from secondaries. Both read concern and write concern must be set to “majority”, as explained in the MongoDB manual. “Majority” is the default write concern, so I configured only the read concern explicitly.
How does MongoDB ensure causal consistency? It uses a logical clock (aka a Lamport clock) called clusterTime to partially order events across all servers in a replica set or sharded cluster. Whenever the client sends a write operation to a server, the server advances its logical clock and returns the new clock value to the MongoClient. Then, if the MongoClient’s next message is a query, it passes the afterClusterTime parameter, which asks the server to return data including all writes up to that clusterTime. If the server is a lagged secondary, it waits until has sufficiently caught up:

If you query a secondary that hasn’t yet caught up to that point in time, according to the logical clock, then your query blocks until the secondary replicates to that point. (Yes, the parameter is called afterClusterTime, but the secondary only needs to replicate up to that clusterTime, not after it.)
The Fine Print #
As I said, causal consistency requires write concern “majority” (the default) and read concern “majority” (not the default). Other configurations give weaker guarantees, see the thorough documentation.
Your client-side session object tracks, in memory, an ever-increasing clusterTime value, which it exchanges with every MongoDB server it talks to. If you lose the clusterTime, you lose causal consistency. Thus you must use the same MongoClient and the same session object throughout. Except, it’s possible to…
Transfer the clusterTime #
Here’s the trick we should’ve publicized: you can transfer the clusterTime from one session to another. The sessions can’t be concurrent—you must wait for one session to end before you use the next one—but even if the sessions belong to different MongoClients, or different processes, or they run on different machines, they’ll form a causally consistent chain.
Continuing the example above, inside the “with start_session” block, capture the session’s clusterTime and operationTime:
with client.start_session() as s:
posts_collection.insert_one(
{"user_id": "Liam", "contents": "I'm very witty"}, session=s)
cluster_time = s.cluster_time
operation_time = s.operation_time
Now you have logical clock values from the primary after it inserted the post. You can create a new session, optionally on a different client or even a different machine, and fast-forward its logical clock:
client2 = MongoClient("mongodb://srv1,srv2,srv3/?replicaSet=rs")
# Same get_collection args as before.
posts_collection2 = client2.db.get_collection(
"posts",
read_preference=ReadPreference.SECONDARY,
read_concern=ReadConcern("majority"))
with client2.start_session() as s2:
s2.advance_cluster_time(cluster_time)
s2.advance_operation_time(operation_time)
user_posts2 = list(
posts_collection2.find({"user_id": "Liam"}, session=s2))
After you call advance_cluster_time and advance_operation_time, subsequent operations on that session (don’t forget the session parameter!) are guaranteed to reflect all changes up to that time.
See the MongoDB Manual’s example code for transferring logical clocks with each driver.
Not So Convenient #
Why do you need to transfer two clock values between sessions, instead of one? It’s bad API design; it reveals implementation details that could have and should have been hidden. I was in a rush during the MongoDB 3.6 cycle and I didn’t take the time to understand our logical clocks and propose a convenient API. It’s hard to change now, millions of people depend on the current APIs, but some MongoDB engineers are pushing to fix it.
Anyway, transferring two values isn’t so bad, the real inconvenience is piping these values through the layers of your application stack. If you use MongoDB in your web application, you probably have something like this:
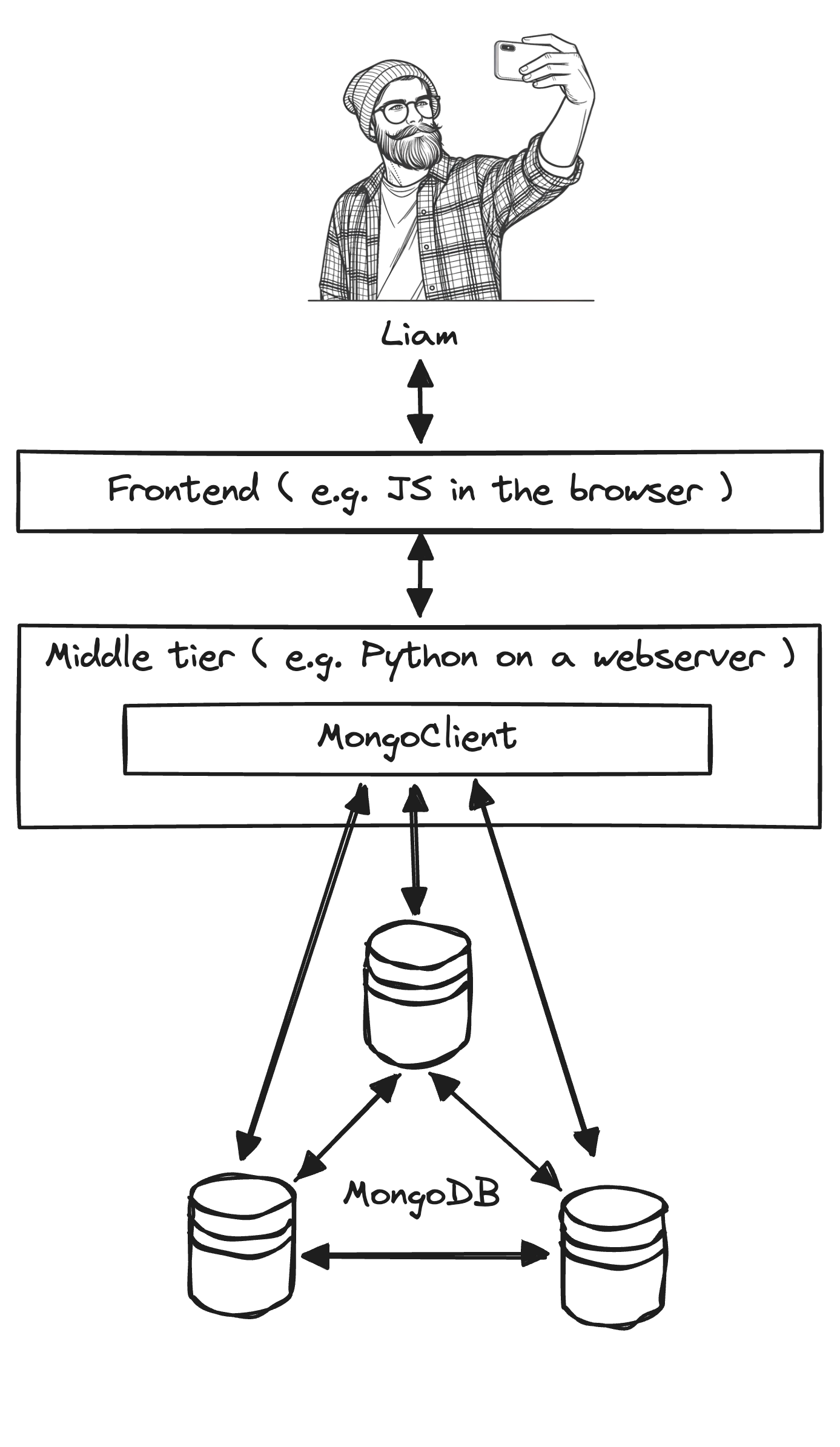
Guaranteeing causal consistency with this architecture is toilsome. When Liam posts his witticism, he clicks a button in the frontend (a Javascript web app in this example), which sends the post to the middle tier, which calls insert with the MongoDB driver. Then the middle tier must capture the session’s clusterTime and operationTime, and return them to the frontend, which saves them in web storage. When Liam refreshes the page, the frontend must load the clusterTime and operationTime from web storage and send them with its request to the middle tier, which uses them to call advance_operation_time and advance_cluster_time on its session before executing find on a secondary. This guarantees Liam sees his post, but what a pain in the tuchus!
In the years since MongoDB 3.6, we could’ve documented this process better, and encouraged framework authors to build it into their application frameworks to ease the burden on developers. We didn’t do that. As far as I know, causal consistency is rarely used. It’s a shame, since it’s performant and conceptually simple.
It’s not too late to make causal consistency popular. If you want to help (especially if you maintain a multi-tier app framework), please write to me! But I now guess that consistent secondary reads without application logic are the real solution. I hope to research it later this year.
Further Reading #
- Read Isolation, Consistency, and Recency in the MongoDB Manual.
- Implementation of Cluster-wide Logical Clock and Causal Consistency in MongoDB.
- Tunable consistency in MongoDB.
- Checking Causal Consistency of MongoDB.
- The MongoDB driver specification for causal consistency.
- Adapting TPC-C Benchmark to Measure Performance of Multi-document Transactions in MongoDB, this paper uses causally-consistent reads in its benchmark.