New Driver Features for MongoDB 3.6
At MongoDB World this week, we announced the big features in our upcoming 3.6 release. I’m a driver developer, so I’ll share the details about the driver improvements that are coming in this version. I’ll cover six new features—the first two are performance improvements with no driver API changes. The next three are related to a new idea, “MongoDB sessions”, and for dessert we’ll have the new Notification API.
Table Of Contents
Wire Protocol Compression #
Since 3.4, MongoDB has used wire protocol compression for traffic between servers. This is especially important for secondaries streaming the primary’s oplog: we found that oplog data can be compressed 20x, allowing secondaries to replicate four times faster in certain scenarios. The server uses the Snappy algorithm, which is a good tradeoff between speed and compression.
In 3.6 we want drivers to compress their conversations with the server, too. Some drivers can implement Snappy, but since zLib is more widely available we’ve added it as an alternative. When the driver and server connect they negotiate a shared compression format. (If you’re a security wonk and you know about CRIME, rest easy: we never compress messages that include the username or password hash.)
In the past, we’ve seen that the network is the bottleneck for some applications running on bandwidth-constrained machines, such as small EC2 instances or machines talking to very distant MongoDB servers. Compressing traffic between the client and server removes that bottleneck.
OP_MSG #
This is feature #2. We’re introducing a new wire protocol message called OP_MSG. This will be a modern, high-performance replacement for all our messy old wire protocol. To explain our motive, let’s review the history.
Ye Olde Wire Protocol #
First, we had three kinds of write messages, all unacknowledged, and also a message for disposing a cursor:

Ye Olde Wire Protocol
There were also two kinds of messages that expected a reply from the server: one to create a cursor with a query, and another to get more results from the cursor:

Ye Olde Wire Protocol
Soon we added another kind of message: commands. We reused OP_QUERY, defining a command as a query on the fake $cmd collection. We also realized that our users wanted acknowledged writes, which we implemented as a write message immediately followed by a getLastError command. That brings us to this picture of Ye Olde Wire Protocol:
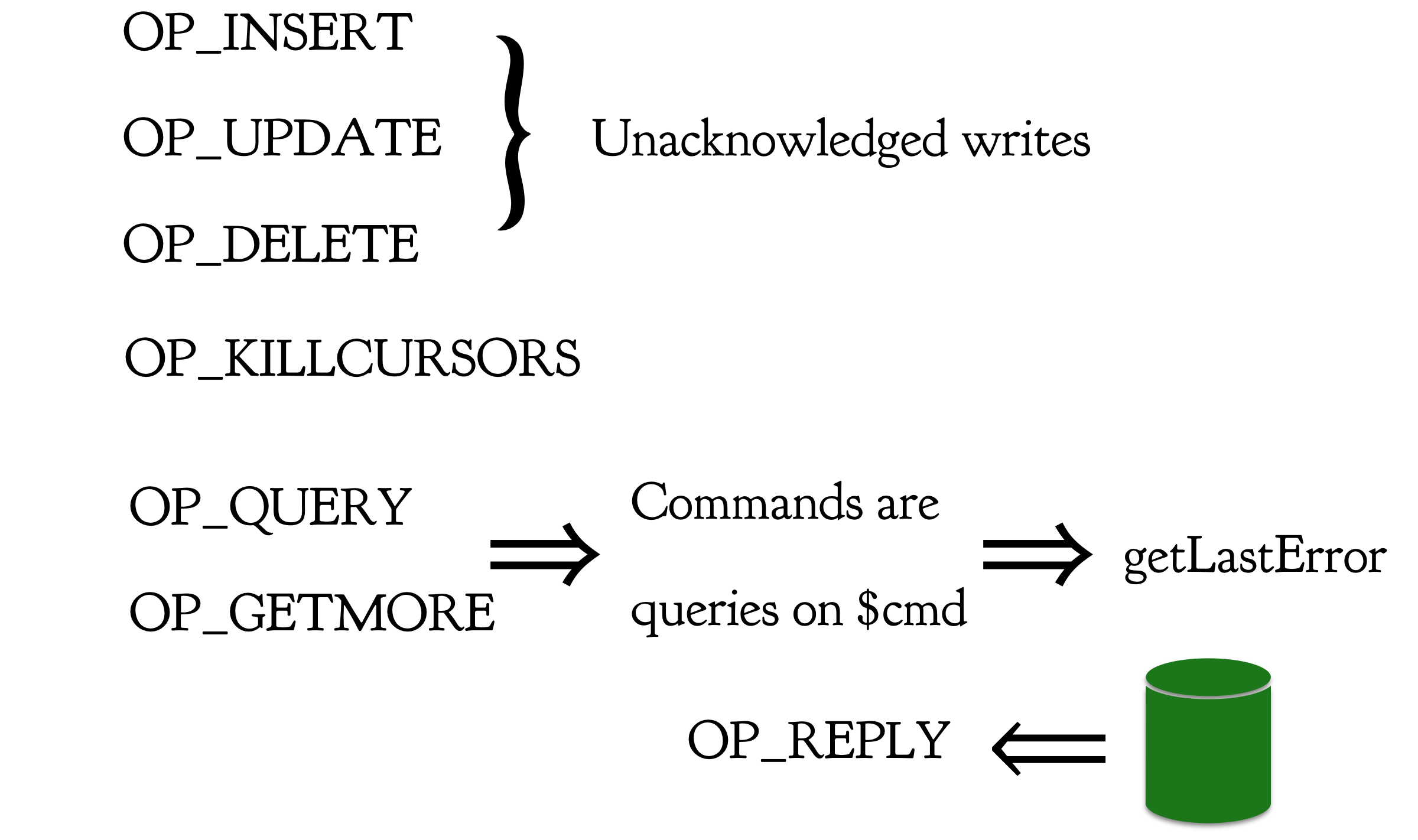
Ye Olde Wire Protocol
This protocol served us remarkably well for years: it implemented the features we wanted and it was quite fast. But its messiness made our lives hard when we wanted to innovate. We couldn’t add all the features we wanted to the wire protocol, so long as we were stuck with these old message types.
Middle Wire Protocol #
In MongoDB 2.6 through 3.2 we unified all the message types. Now we have the Middle Wire Protocol, in which everything is a command:

Middle Wire Protocol
This is the wire protocol we use now. It’s uniform and flexible and has allowed us to rapidly add features, but it has some disadvantages:
- Still uses silly OP_QUERY on
$cmdcollection - No unacknowledged writes
- Less efficient
Why is it less efficient? Let’s see how a bulk insert is formatted in the Middle Wire Protocol:

Middle Wire Protocol
The “insert” command has a standard message header, followed by the command body as a single BSON document. In order to include a batch of documents in the command body, they must be subdocuments of a BSON array. This is a bit expensive for the client to assemble, and for the server to disassemble before it can insert the documents. The same goes for query replies: the server must assemble a BSON array of query results, and the client must disassemble it.
Compare this to Ye Olde Wire Protocol’s OP_INSERT message:
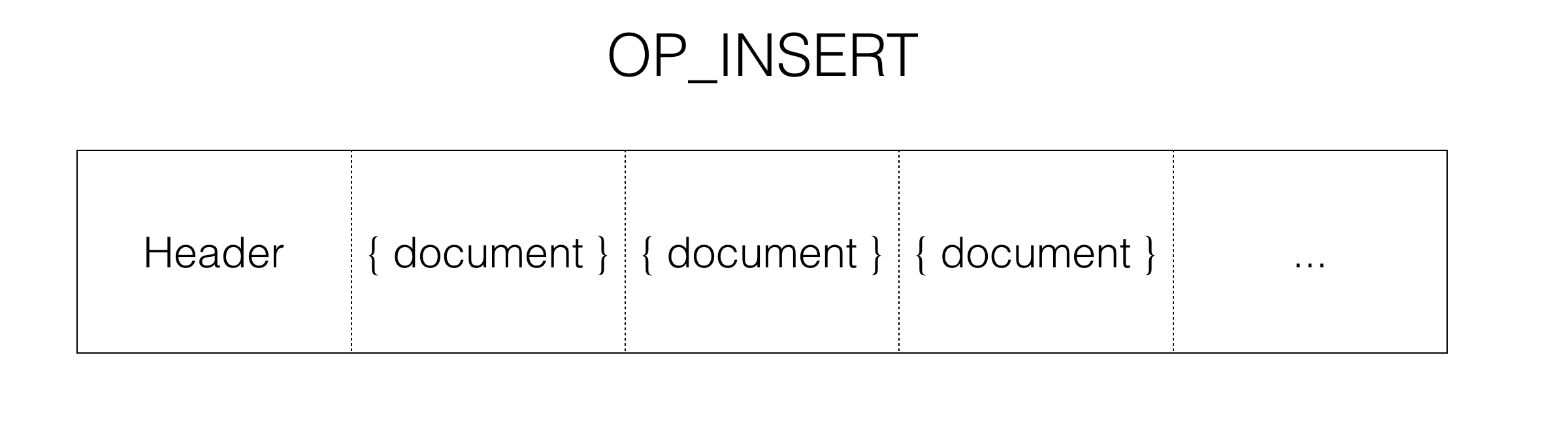
Ye Olde Wire Protocol
Ye Olde Wire Protocol’s bulk insert message was simple and efficient: just a message header followed by a stream of documents catenated end-to-end with no delimiter. How can we get back to this simpler time?
Modern Wire Protocol #
This winter, we’ll release MongoDB 3.6 with a new wire protocol message:
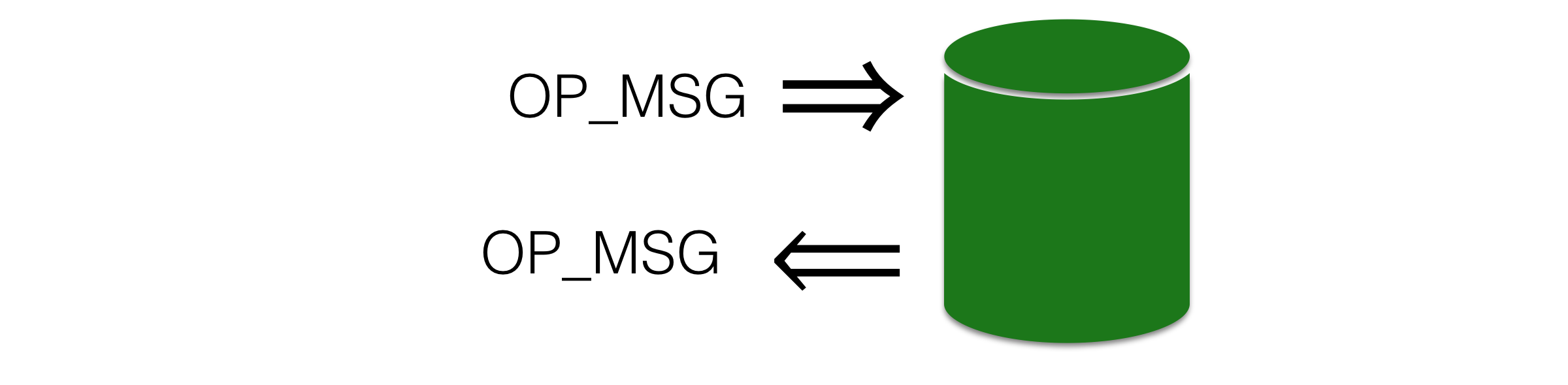
Modern Wire Protocol
For the first time, both the client and the server use the same message type. The new OP_MSG will combine the best of the old and the middle wire protocols. It was mainly designed by Mathias Stearn, a MongoDB veteran who applied the lessons he learned from our past protocols to make a robust new format that will stand the test of time.

OP_MSG
- Header: this is the same header as for all the other messages, with the message length and so on.
- Flags: so far we’ve defined three flags: exhaustAllowed, moreToCome, and checkSumPresent. A client can set “exhaustAllowed” to tell the server that the client supports exhaust cursors. The client sets “moreToCome” for unacknowledged writes: the server knows the client will send more messages without expecting a server reply. A server message with “moreToCome” is an exhaust cursor. And finally, “checkSumPresent” is set if the last section is a checksum, so the receiver knows whether it should checksum the message as it reads it, in order to compare with the checksum at the end.
- Body: this is the standard command document, like
{"insert": "collection"}, plus write concern and other command arguments. It does not have to contain a BSON array of documents, however. - Document Stream: the big win comes here. This is the same simple format as Ye Olde Wire Protocol, which is very efficient to assemble and disassemble.
- Checksum: An optional CRC-32C checksum. We’ve seen cases where bad hardware can corrupt documents on the wire, despite the parity bits at various layers of the network stack. Checksumming in the MongoDB protocol will protect you from corruption at no significant performance cost.
OP_MSG is the one message type to rule them all. We’ll implement it in stages. For 3.6, drivers will use document streams for efficient bulk writes. In subsequent releases the server will use document streams for query results, and we’ll add exhaust cursors, checksums, and unacknowledged writes. OP_MSG is extensible, so it will probably be our last big protocol change: all future changes to the protocol will work within the OP_MSG framework.
You’ll get faster network communications from compression and OP_MSG as soon as you upgrade your driver and server, without any code changes. The remaining four features, however, do require new code.
Retryable Writes #
Currently, statements like this are very convenient with MongoDB but they’re a bit unsafe:
collection.update_one({'_id': 1}, {'$inc': {'x': 1}})
Here’s the problem: what happens if your program tries to send this “update” message to the server, and it gets a network error before it can read the response? Perhaps there was a brief network glitch, or perhaps the primary stepped down. It’s not always possible to know whether the server received the update before the network error or not, so you can’t safely retry it; you risk executing the update twice.
Last year at MongoDB World, I gave a 35-minute talk about how to make your operations idempotent so they could be safely retried, and I wrote a 3000-word article. All that is about to be obsolete. In MongoDB 3.6, the most common write messages will be retryable, safely and automatically.
client = MongoClient('mongodb://srv1/?retryWrites=true')
collection = client.db.my_collection
collection.insert_one({'_id': 1, 'n': 0})
collection.update_one({'_id': 1},
{'$inc': {'n': 1}})
collection.replace_one({'_id': 1},
{'n': 42})
collection.delete_one({'_id': 1})
If any of these write operations fails from a network error, the driver automatically retries it once. This is safe to do now, because MongoDB 3.6 stores an operation ID and the outcome of each write. If the driver sends the same operation twice, the server ignores the second operation, but replies with the stored outcome of the first attempt. This means we can do an update like $inc exactly once, even if there’s a flaky network or a primary stepdown.
Most of the write methods you use day-to-day will be retryable in 3.6, like the CRUD methods above or the three findAndModify wrappers:
old_doc = collection.find_one_and_update({'_id': 2},
{'$inc': {'n': 1}})
old_doc = collection.find_one_and_replace({'_id': 2},
{'n': 42})
old_doc = collection.find_one_and_delete({'_id': 2})
Operations that affect many documents, like update_many or delete_many, won’t be retryable in this release. But bulk inserts will be retryable in 3.6:
collection.insert_many([{'_id': 1}, {'_id': 2}])
Causal Consistency #
Until now, reading from secondaries was unpredictable. You couldn’t guarantee that between the time your program writes to the primary and when it reads from a secondary, that the secondary has replicated the write. Therefore programs that must read their writes can only read from the primary. Furthermore, if you spread your reads among secondaries, then results from different secondaries might jump back and forth in time.
With the new versions of all our drivers you can reliably read your writes and do monotonic reads, even when reading from secondaries. To support this feature we introduce “sessions”:
client = MongoClient('mongodb://srv1,srv2,srv3/?replicaSet=rs')
collection = client.db.get_collection(
"my_collection",
read_preference=ReadPreference.SECONDARY)
with client.start_session() as s:
# The update message goes to the primary.
collection.update_one({'_id': 1}, {'$set': {'x': 0}}, session=s)
# Read your write, even when reading from a secondary!
collection.find_one({'_id': 1}, session=s)
# This query returns data at least as new as the previous query,
# even if it chooses a different secondary.
collection.find_one({'_id': 2}, session=s)
In 3.6, a causally consistent session will let you read your writes and guarantee monotonically increasing reads from secondaries. It even works in sharded clusters!
The design, by Misha Tyulenev, Randolph Tan, and Andy Schwerin, uses a Lamport Clock to partially order events across all servers in a replica set or sharded cluster. Whenever the client sends a write operation to a server, the server notes the Lamport Clock value when the write was executed, and returns that value to the client. Then, if the client’s next message is a query, it asks the server to return query data that is causally after that Lamport Clock value:
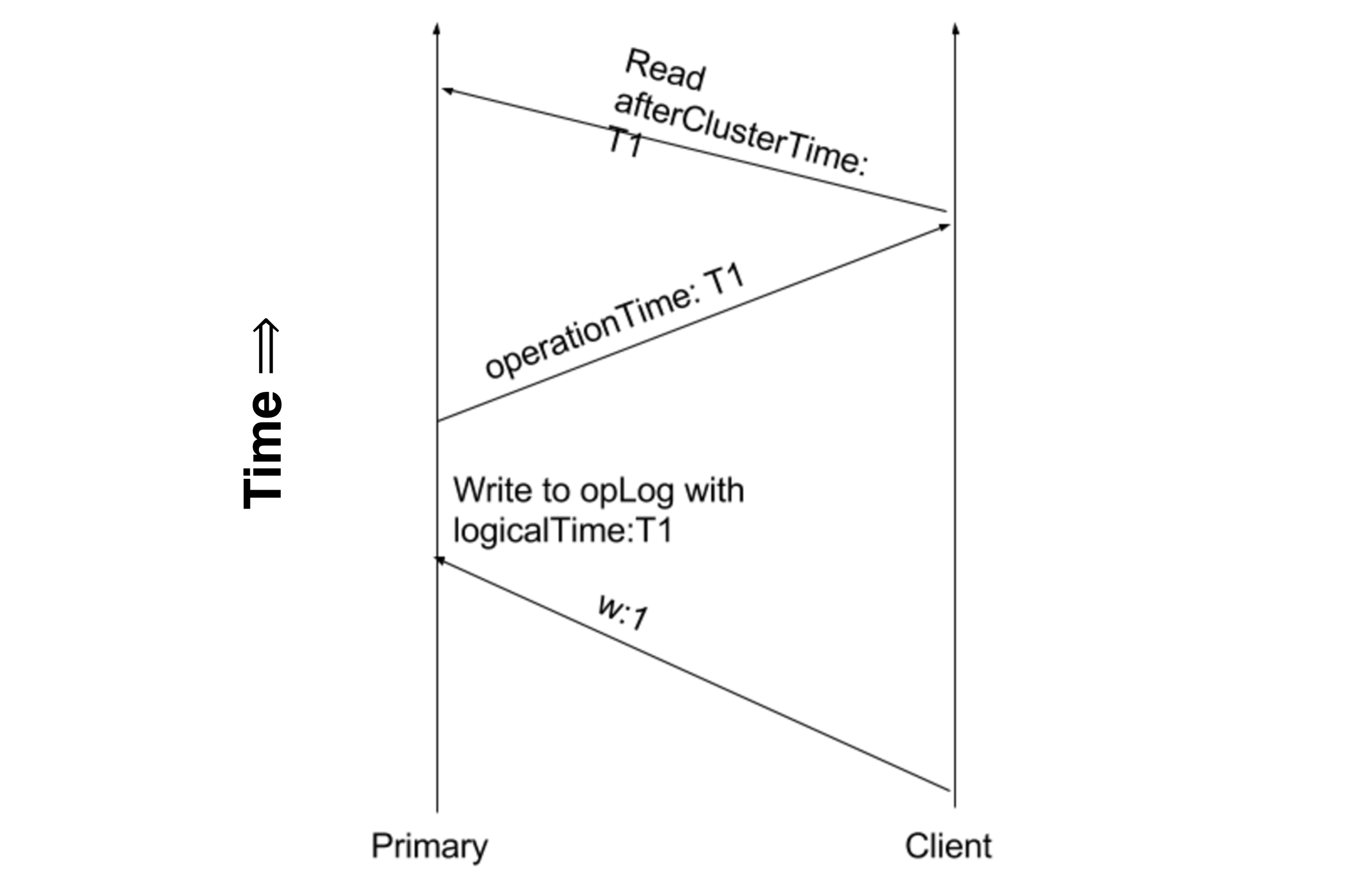
Causal ordering of events by Lamport Clock values
If you query a secondary that hasn’t yet caught up to that point in time, according to the Lamport Clock, then your query blocks until the secondary replicates to that point. Yes, I know that in the diagram above we call the same value either “logicalTime”, “operationTime”, or “clusterTime” depending on the context. It’s complicated. Here’s the gist: this feature ensures that you can read your writes when reading from secondaries, and that each secondary query returns data causally after the previous one.
Change Streams #
Now it’s time for dessert! MongoDB 3.6 will have a new change notification API, called a “change stream.” You can subscribe to changes in a collection and you can filter or transform the change notifications using an aggregation pipeline before you process them in your program:
change_stream = client.test.collection.watch([
{'$match': {
'operationType': {'$in': ['insert', 'replace']}
}},
{'$match': {
'fullDocument.n': {'$gte': 1}
}}
])
# Loops forever.
for change in change_stream:
print(change)
This code shows how you’ll use a change stream in PyMongo. The collection object will have a new method, “watch”, which takes an aggregation pipeline. In this example we listen for all inserts and replaces in a collection, and filter these change notifications to include only documents whose “n” field is greater than or equal to 1. The result of the “watch” method is a cursor that emits changes as they occur.
In the past we’ve seen that MongoDB users deploy a Redis server on the side, just for the sake of change streams, or they use Meteor to get notifications from MongoDB. In 3.6, these notifications will be a MongoDB builtin feature. If you were maintaining both Redis and MongoDB, soon MongoDB alone will meet your needs. And if you want change streams but you aren’t using Javascript and don’t want to rely on Meteor, you can write your own change system in any language without reinventing Meteor.
Change streams have two main uses. First, if you’re keeping a second system like Lucene synchronized with MongoDB, you don’t have to tail the oplog anymore. We now offer a well-designed API that lets you subscribe to changes which you can apply to your second system. The other use is for collaboration: when one user changes a shared piece of data, you want to update other users’ views. Change streams will make collaborative applications easy to build.
I’m a coder, not a bullshitter, so I wouldn’t say this if it weren’t true: MongoDB 3.6 is the most significant advance in client-server features since I started working here more than five years ago. Compression will remove bottlenecks for bandwidth-limited systems, and OP_MSG paves the way for much more efficient queries and bulk operations. Retryable writes and causal consistency add guarantees that MongoDB users have long wished for. And change streams makes MongoDB a natural platform for collaborative applications.