Paper Review: Rex: Replication at the Speed of Multi-core
Rex: Replication at the Speed of Multi-core by Zhenyu Guo, Chuntao Hong, Mao Yang, Dong Zhou, Lidong Zhou, and Li Zhuang at EuroSys 2014.
Like the C5 paper I just reviewed, Rex is about improving asynchronous replication performance on multi-core, but I thought the C5 paper was humdrum whereas Rex is thought-provoking.
Warm up your neurons because they're going to get a workout.
Background #
Usually in asynchronous replication, one server is the leader for a while and makes modifications to its data. It logs these modifications in a sequence, which it streams to followers. They replay these modifications to their copies of the data, in the same order. Thus there is a total order of states; any state that the leader passes through is eventually reflected on each follower in the same order. Clients can read from the leader or followers, and they’ll see the same sequence of states, although the followers may lag.
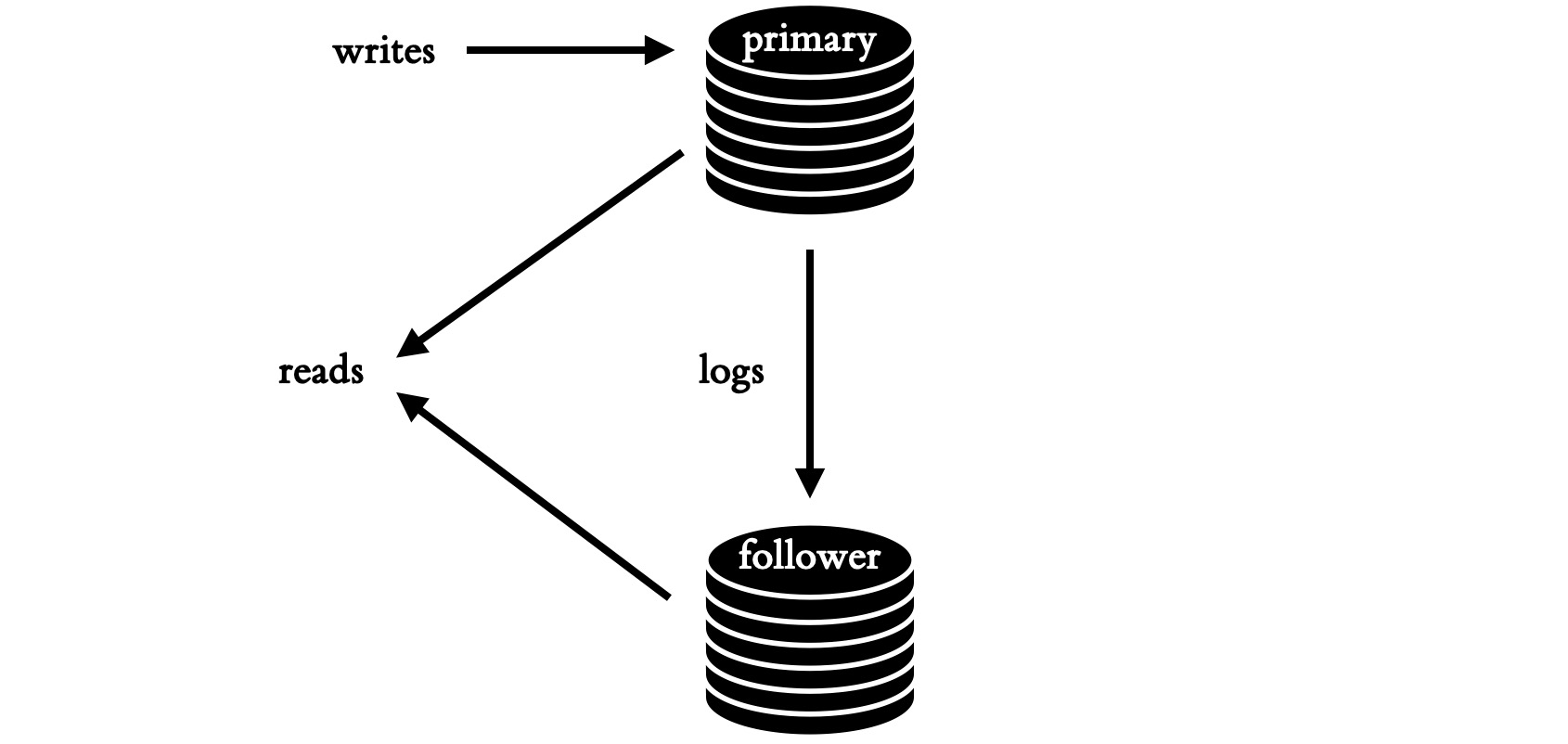
So far so good. Distributed Systems 101.
But what if it didn’t have to be that way?
Galaxy brain.
Partial-Order Replication #
The Rex paper’s insight is, the leader only needs to guarantee a partial order of events. On the leader if two transactions are running on concurrent threads t1 and t2 and they attempt to modify the same data x, some concurrency protocol decides the outcome. For example, if your database wants to guarantee serializability, it might use two-phase locking. Let’s say t1 gets the write-lock L on x first and updates x, then unlocks L. Then, t2 locks L, updates x, and unlocks L. This sequence of events guarantees that t1’s write happens-before t2’s, and the value of x after both transactions commit is the value t2 wrote.
(Forgive me, this will get interesting in a second.)
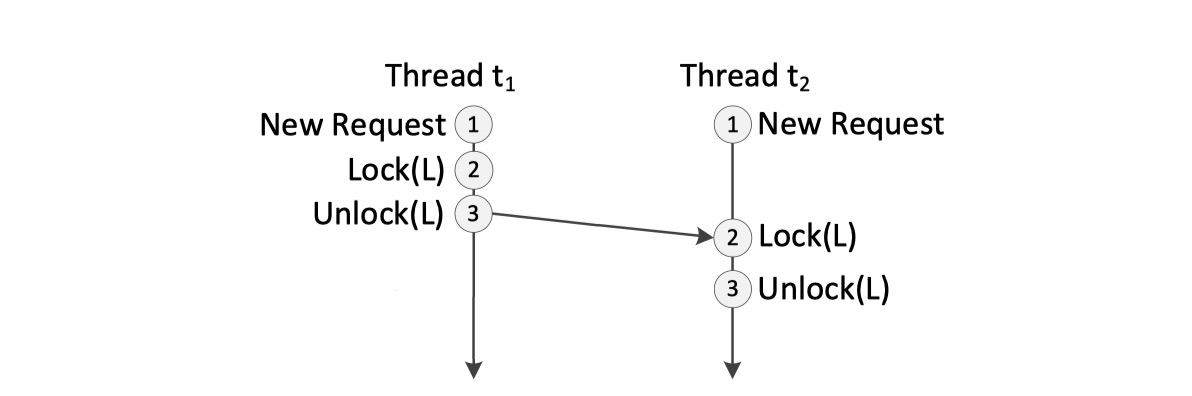
I adapted this from the author's Figure 2.
On the other hand if a pair of threads t3 and t4 write to disjoint data, they’ll share no locks and their writes are concurrent: neither one happened before or after the other.
(OK, now it’s going to get interesting.)
The Rex leader logs all the lock/unlock events executed by t1, t2, t3, and t4. But it does not decide what order they occur! It only logs that t1’s unlock happens-before t2’s lock, then streams that information to the followers. So followers learn about a partial order of lock/unlock events, and replay them in some order that matches the leader’s partial order. Each follower is free to replay them in whatever order it wants so long as it obeys the rule, “t1 unlocks L before t2 locks L”. Thus followers can execute with as much parallelism as the leader did, allowing higher throughput than if they had to execute the writes in some total order.
My example above is for a database that guarantees serializability, and its mechanism is two-phase locking. But any guarantee and any mechanism would work with Rex. The point is that the primary decides what happens-before relationships must be obeyed, and the followers obey them.
The Rex authors observe that followers in most systems suffer low parallelism, because they’re obeying a total order for the sake of consistency, but:
This tension between concurrency and consistency is not inherent because the total ordering of requests is merely a simplifying convenience that is unnecessary for consistency.
We’ll revisit this claim below; I have concerns about “consistency”.
Capturing Partial Order #
How does the leader learn the partial order of writes and transmit it to the followers? In Rex, locks are wrapped with a shim which captures happens-before relationships on the leader, and enforces them on the followers. The Rex authors call these relationships “causal edges”:
// Pseudocode of the Lock and Unlock wrappers.
class RexLock {
public:
void Lock() {
if (env::local_thread_mode == RECORD) {
AcquireLock(real_lock);
RecordCausalEdge();
} else if (env::local_thread_mode == REPLAY) {
WaitCausalEdgesIfNecessary();
AcquireLock(real_lock);
}
}
void Unlock() {
if (env::local_thread_mode == RECORD) {
RecordCausalEdge();
}
ReleaseLock(real_lock);
}
};
So if t1 unlocks L on the leader and then t2 locks it, L records that the second event depends on the first, in RecordCausalEdge. Rex sends this information to the followers, who wait for t1 to unlock L before t2 locks it, with WaitCausalEdgesIfNecessary. This happens whether t2 actually has to wait to lock L on the leader, or just locks L some time after t1 unlocks it.
The paper doesn’t describe the exact format of the log, but the log somehow expresses which threads executed which operations, and the order in which they acquired and released every lock. Visually it’s a DAG:
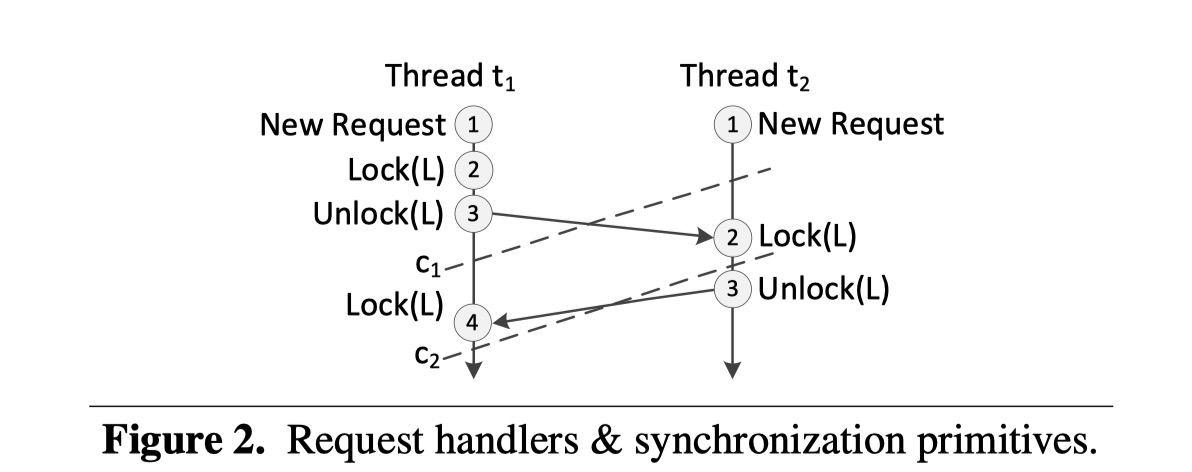
The lines labeled “c1” and “c2” are two possible cuts through the DAG. The authors say:
A cut is consistent if, for any causal edge from event e1 to e2 in the trace, e2 being in the cut implies that e1 is also included in the cut. An execution reaches only consistent cuts. Figure 2 shows two cuts c1 and c2, where c1 is consistent, but c2 is inconsistent.
“Consistent” here seems a bad choice of jargon, we’ve so overloaded that poor word already. In any case, a cut is ready to be packed up and shipped to the secondaries so long as it doesn’t slice across a causal edge the wrong way. If the primary sent all the events above c2 to the secondary, the secondary thread t1 would be stuck at its event 4, because it’s waiting for t2’s event 3, which isn’t included in the cut. No such hangup occurs if the primary uses the “consistent” cut c1.
For this definition to work, imagine that each cut includes all events to the beginning of time. In practice, of course, the primary only has to send events that are in the newest cut and not in previous cuts.

Annoying Details #
I skimmed Section 3, which buries the reader in Paxos junk. It describes how leaders are demoted or elected, how servers are added or removed, how intermediate states are checkpointed for the purposes of crash-recovery, rollback, and garbage collection. I sympathize with the authors: they had to describe their ideas in terms of Paxos, the main consensus protocol in 2014, and Paxos has so much ambiguity and variation that the authors must detail their choices about every aspect of the protocol. If they’d come just a bit later they could have built on Raft instead and taken a lot of these details for granted, focusing on their main contribution instead.

My Evaluation #
The Rex authors want to increase replication throughput by improving parallelism on secondaries. They claim Rex is “a new multi-core friendly replicated state-machine framework that achieves strong consistency while preserving parallelism in multi-thread applications.” I agree that the protocol is multi-core friendly, but C5 is a simpler way to achieve that goal, and as in my review of the C5 paper, I’ll warn that parallelism alone won’t save you from replication lag.
What do the authors mean when they say Rex “achieves strong consistency”? That word is so pathologically abused, it has at least two meanings in this paper alone! In the sentence above, “consistency” seems to mean what we usually call “convergence”: if you stop sending writes to the primary, eventually all replicas will have the same state. From a client’s point of view this is “eventual consistency”, and it’s parsecs from the usual meaning of “strong consistency”. See Pat Helland’s Don’t Get Stuck in the “Con” Game. I’ll forgive the authors, there’s been a lot of work since 2014 to clarify our jargon.
Leaving jargon aside, what’s the user experience when querying a Rex secondary? There’s no guarantee besides convergence. Independent events happen in different orders on different secondaries, temporarily producing states that never existed on the primary. Other systems such as MongoDB have weak guarantees on secondaries but we’re able to build stronger consistency on top of them. For example, MongoDB guarantees causal consistency on secondaries by reading at the majority-committed timestamp. We make this guarantee and also achieve high parallelism during replication (see the C5 review). MongoDB’s guarantee relies on its ability to read a past snapshot on all replicas at a specific timestamp. This is either impossible with Rex, or would require a degree of coordination that I suspect would obviate Rex’s advantage.
The Rex paper expanded my mind with the idea of partial-order replication, but I don’t immediately see a practical use for it.
Images from The Principles of Light and Color, Edwin D. Babbit 1878.