Antithesis BugBash Conference 2026
This was my second BugBash, and it’s still my favorite conference—the right combination of industry and academia, research and practice. (See last year’s notes and this year’s agenda and my colleague Murat’s summaries.) The crowd was bigger this year, and I was happy that the speaker lineup included more women. The Antithesis product itself is innovative and important, and the conference is collecting the software-verification and distributed-systems people I want to meet and collaborate with.
Antithesis tutorial #
Antithesis encouraged us to sign up for their tutorial. They gave us a GitHub project with a little Python echo server containing a few bugs (memory leak, crash, or wrong response if a random number is divisible by one million). Once Antithesis gave me permissions on the repo, I could run a GitHub action that ran a half-hour test in Antithesis and generated a report in their web UI. I played with the log explorer, which shows when a log message appears—not in a timeline, but in the tree of execution branches.
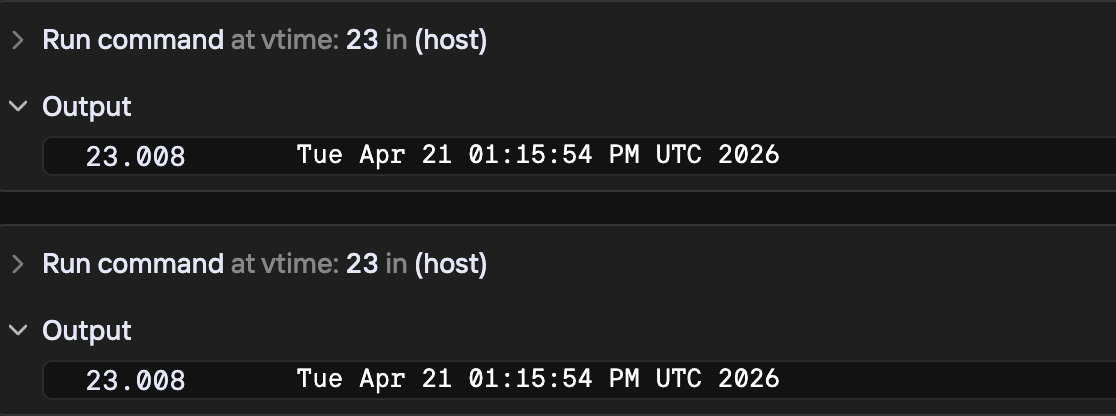
I also tried their time-travel debugger: you can run any bash command at any virtual time along any branch. I ran “ls”, “ps”, and “date” and they worked as expected. Running “date” twice at the same timestamp gives the same result, because the clock is simulated. Pretty cool.
Wednesday #
Integrating formal verification into AI-assisted development workflows #
Nada Amin (Harvard SEAS) and Fernanda Graciolli (Midspiral)
They proposed two pipelines. First: a human defines properties, an LLM writes Dafny that upholds them, and Dafny is auto-compiled to JavaScript. The catch is that the generated JS is bloated and slow—e.g., it must use BigNums for all ints to match Dafny’s integer semantics. Second: existing JS gets pre/postconditions added, then it’s translated to Dafny and proven. They have a toolchain called LemmaScript, which is TypeScript with manually-added annotations that allow translation to Dafny or Lean for proof.
They say AIs are better at Dafny proofs than at Lean proofs, perhaps because Lean error messages tend to lead the LLM down rabbit holes and lose sight of the overall goal, whereas Dafny is somehow better.
I asked, “Is an incremental change to a spec incrementally easy to re-prove?” The answer: sometimes!
What is test coverage in distributed systems? #
Rohan Padhye (CMU)
A terrific talk—Padhye has a lot of the same interests I do. He asks: what sort of coverage should we measure? It could be all global states (but that space is usually infinite), some abstraction over states, all schedules of message deliveries, or all combinations of faults (e.g., a simultaneous election and disk failure).
We need some abstraction (like a VIEW in TLA+) to define the equivalence class of things we measure, then maximize coverage of those classes. Symmetry reduction is one tactic. Or treat two behaviors with the same happens-before relation as equivalent even if the clock order differs (Dynamic Partial-Order Reduction for Model Checking Software, Flanagan & Godefroid 2005). A cheaper version is “happens-before pair coverage”: for every pair of abstract event types, have I seen both orderings, A→B and B→A? Extends to k-tuple coverage for deeper interactions: have I seen all orderings of A, B, and C? You have to decide whether there’s some upper bound on k where you’ve probably found all the bugs. The “Mallory” system builds on Jepsen, fuzzing distributed systems and rewarding paths that discover new happens-before pairs of events. Mallory uses a locality-sensitive hash function (“MinHash”) to measure how similar events are, rather than a human-built event-abstraction function.
A Randomized Scheduler with Probabilistic Guarantees of Finding Bugs depends on the “small model hypothesis”: that most bugs need only depth-d specific ordering constraints. The paper estimates the probability of finding depth-d bugs in n runs. Padhye says Microsoft has an empirical study of how deep bugs typically are; I think he meant the CHESS paper, which says most concurrency bugs can be reproduced with only two thread preemptions. An independent replication on the SCTBench benchmark suite (Thomson, Donaldson, Betts, TOPC 2016) confirms that most bugs surface with 1–2 preemptions, though one needed five.
Peter Alvaro was in the room and noted that there are taxonomies and lists of known distributed-systems bugs — e.g. the TaxDC taxonomy (Leesatapornwongsa et al., ASPLOS 2016) of 104 distributed concurrency bugs from Cassandra, Hadoop MapReduce, HBase, and ZooKeeper, and the broader Cloud Bug Study database (Gunawi et al., SoCC 2014) covering 3,655 vital issues across six cloud systems. For a given well-known bug type, you could check whether another system has it by trying to reproduce. Is that relevant to my AI-driven spec-behavior exploration?
FuzzBench is a benchmark of fuzzers worth looking at.

Thursday #
We won, what now? #
Will Wilson (Antithesis)
AI has suddenly inspired everyone to care about software correctness. Will warns that we’re entering an Eternal September: a flood of new people and money will be interested in our topics (DST, formal methods, PBT). We should welcome them, but also be prepared to be annoyed. Don’t resent them for taking our ideas and profiting without crediting us.
Where all the ladders start #
Peter Alvaro (UC Santa Cruz)
A history of failed attempts to find a silver bullet for correct distributed systems.
Is concurrency the problem with distributed systems? Peter contrasts distributed deadlock detection (search for cycles, monotonic: once you find a cycle, no new info will tell you it doesn’t exist) vs. distributed GC (search for unreferenced subgraphs, nonmonotonic: new info can tell you garbage is non-garbage). CRDTs are monotonic, can be verified by static analysis, and avoid coordination. Are CRDTs the silver bullet? No, it’s hard to know when the computation is finished, and few people enjoy programming this way. (Another way to say this: CRDTs require coordination for reads, not writes.)
Is uncertainty the problem? If so, observability is the answer. Distributed systems operate in the dark, from humans’ perspective, we need to turn the lights on. Peter describes “derivation counting”: if a fact can be derived two ways and one way is invalidated, the fact is still true. This leads to his lineage-driven fault injection (LDFI) paper. If you think of a distributed system as a query, you can ask whether the query still returns “true” after some faults—if so, the system is fault-tolerant for those faults. LDFI found bugs in Netflix systems and got some industry interest. But “the lights have not been turned on”: observability hasn’t been rolled out to the extent he desires, or the extent that LDFI requires. Also, LDFI analysis prompts you to add more redundancy, but more redundancy can be a bad thing.
Metastable failures. Peter paraphrases Metastable Failures in the Wild and his own paper Formal Analysis of Metastable Failures in Software Systems. He describes a simulator with a DSL for exploring metastable failures. His version doesn’t just simulate: it also uses CTMCs for analysis to speed up the search compared to running millions of simulations. Peter says it doesn’t work yet—getting the CTMC, the simulation, and the actual system to agree is too hard and manual. (He may have undersold his own past work here, I recall the paper had positive results.) A promising new direction is DesCartes, a Rust simulator that explores performance rather than correctness, using the production code.
(DesCartes looks really cool to me. It’s connected with my own interests in using simulation to estimate protocol performance, as I did in the LeaseGuard paper, or using TLA+ for performance modeling.)

What 20 years of kernel bugs taught us about finding the next one #
Jenny Qu (Pebblebed)
She analyzed 125k bugs; the average age was over 2 years, with some much longer-lived. Most long-lived kernel bugs are race conditions, which persist for years because they’re so hard to reproduce. She trained an AI to guess whether a commit was risky.
Informal methods #
Ben Eggers (OpenAI)
Coding hasn’t changed much: it’s still a stochastic, unreliable process. Now more than ever, you need to make careful up-front design decisions. A human must design the schema, API, and behavioral contracts. Eggers guesses that prompts will become “math-like” in their precision. Humans might also write all the tests, or at least some of them.
“Code got cheap, correctness did not.”

Protocol-aware deterministic simulation testing #
Chaitanya Bhandari (TigerBeetle)
I missed this one while I was recording a “podcast episode” with Carl Sverre about the future of testing and verification. It sounds like it’s in my Venn diagram, I plan to watch the video.
Fast and fault-tolerant: pick two #
Matt Barrett (Adaptive)
Adaptive runs a trading platform. Their business logic is in single-threaded state machines, with as little concurrency as possible. Predictable low latency is critical. They built “Aeron Cluster”, a fast and fault-tolerant Raft. Surprising that I’d never heard of it! Barrett says they treat each byte as a Raft log entry? Where does the term number go? Aeron introduces a “veto” message: besides merely withholding its vote, a node can actually tell another node that it must not become leader, which apparently prevented a class of operator errors during crises. I wonder which reconfig protocol they chose.
Aeron uses IP multicast and DPDK. Barrett showed a benchmark in Google Cloud, where DPDK works (and apparently IP multicast does too). He showed p99 of 41 microseconds—but that’s pure Raft with no business logic; in practice business logic runs inline and latency goes up. There’s a newer system, Aeron Sequencer, that runs business logic outside of the consensus main path.

Friday #
Building confidence in an always-in-motion distributed streaming system #
Frank McSherry (Materialize)
Frank was at MSR’s distributed-systems lab and is a big deal in database research. Materialize is his startup that does SQL incrementally materialized views: you give it a query, and it continuously updates the answer based on streaming changes from other DBs. It offers serializability and (if you give it a read timestamp) strict serializability. Results are always fresh to within ~1 second.
They use “virtual time” to “pre-resolve non-determinism” and remove logical contention from the critical path. Events are timestamped prescriptively rather than descriptively—the recorded time says when an event should happen, not when it did happen.
He says that thanks to virtual time, parallelism is straightforward: queries get virtual times and serialize easily, and it’s easy to compose systems that share virtual times. If the system is interrupted, when it recovers it fills in past virtual-time events so that, in virtual time, the error never happened.
Borrowing FoundationDB’s simulator for layer development #
Pierre Zemb (Clever Cloud)
They built Materia, a Redis clone, on top of FoundationDB, in Rust. They reused FDB’s DST to test their own code. It revealed lots of bugs and supports a nice dev workflow.

Symbolic execution for invariant discovery (not just bug finding) #
Anish Agarwal (Olympix)
He uses symbolic execution to discover what invariants the code already upholds. A human chooses among the discovered invariants and decides which to keep as requirements. He also discovers almost-upheld invariants, which some paths violate. Perhaps these are invariants the code should uphold and the exceptions are bugs. For more precision, he trains a classifier (not an LLM) to decide whether exceptions are bugs based on their similarity to known past bugs in the code.
Full system fuzzing for Bitcoin #
Niklas Gögge (Brink)
He built a protocol-aware fuzzer, so it sends mostly-valid inputs rather than random bytes; this lets it explore deeper parts of the code instead of having all inputs rejected by the message parser. He mentions Nyx for “fast system snapshotting”—is that an alternative to the Antithesis hypervisor? (Not the whole Antithesis system, of course.) He said at the end he’s “vibe-coding a deterministic hypervisor”, with no more info.

Verifying Cedar Policy’s correctness with PBT and differential response testing #
Lucas Käldström (Upbound)
Cedar is the policy-checker from AWS, now open source. It’s a language for specifying auth policies, with an SMT backend to check them. At AWS they used Lean to prove some properties about the language, and Lean also generated a Rust impl. They handwrote a faster Rust impl and used differential fuzz testing to check the two are equivalent. They also use PBT to test a few properties, mainly that conversions among several text formats of the policy are all lossless.
I think Käldström didn’t personally work on the Cedar implementation, but he’s integrating it with Kubernetes.
Behaviors as the backbone of software correctness #
Gabriela Moreira (Quint)
She uses the TLA+ definition of behavior: a sequence of states or steps. At Informal Systems they wrote TLA+ specs, but the syntax hindered adoption—only a minority of engineers used it. I’m surprised to hear that, I thought that shop was all-in on formal methods! They created Quint four years ago with a different syntax, plus type checking and more static analysis, and recently Quint spun off as a separate company.
The default way to run Quint is simulation, not exhaustive model-checking, since simulation is more intuitive for coders and gives fast feedback. Simulation also finds bugs faster in many situations. She recommends running the simulator many times during spec development, then the model-checker toward the end.
She asks: if you just use the simulator, how do you know when you’re done? The same applies to model-checking: are you sure you modeled everything that matters and wrote all the important properties?
Suggested steps for defining correctness:
- Define a property. Mess up the model and check that the property breaks.
- Model failures (e.g. crashes), and check what happens when there are more faults than your fault-tolerance threshold. There should be a property violation; if not, your properties aren’t strong enough.
- Witnesses, aka vacuity checks. Make sure that safety properties aren’t satisfied by the system doing nothing. (We also call these trigger invariants.) Also, think of the rarest situation you can about your system, see if the tools can find it, and measure how much time/depth it took.
- Reproducible example tests: define Quint behaviors that the spec must allow. Quint lets you add “expectations” in the middle of the sequence—asserts that some property holds at a point along the trace.
- Conformance. There was a DynamoDB outage in October 2025 due to nonconformance with a prose spec. For formal-spec conformance you can do model-based testing, trace checking, or “hybrid”. Hybrid means the model drives testing without controlling everything: try to make the impl follow an example trace, and if it doesn’t, fall back to trace-checking the impl’s actual behavior. Sounds interesting, but she described it only briefly.
The greatest payoff of formal specification is greater understanding, especially when you learn the inductive invariants of your algorithm.
Regarding people who define “spec-driven development” as writing Markdown files for AI: “You’re ruining it.” There’s still time to reclaim “spec-driven development” to mean formal specification!
Model-based testing is much easier with AI: it used to be boring and slow to write and maintain the code, and AI changes that.
I asked, “As formal methods go mainstream, will we keep adding app-specific conformance-checking hooks with AI, or will it become a standardized library?” Quint has a Quint Connect library for conformance checking. It minimizes app-specific code, and the small remaining bits are usually easy for AI. It’s Rust-specific.
Hallway track #
- My colleague Murat Demirbas introduced me to Peter Alvaro. Peter recommends reading more of Yoram Moses’s work “post-Halpern”, after the early-90s material I’ve been reading.
- Liam DeVoe, a Hypothesis maintainer, has joined Antithesis (along with David MacIver) to develop Hegel, which is Hypothesis for non-Python languages. Fun to meet face to face after interacting online.
- Lunch with Gabriela Moreira and her colleague Erick from Quint, joined by Rohan Padhye. We discussed midpoints between simulation and exhaustive model-checking: example traces as unit tests; Hypothesis-style heuristics that explore likely-buggy areas with bug-inducing inputs; trace minimization (search a few steps off each state in a failing trace for shortcuts to a later state); and heuristic exploration / “spec fuzzing” that rewards traces exercising more subexpressions of an invariant. E.g., for an invariant
WRITE_COMMITTED => WRITE_NOT_LOST, the fuzzer first has to find states whereWRITE_COMMITTEDis true beforeWRITE_NOT_LOSTis even evaluated; that progression can guide the search.

Images: David and Marian Fairchild’s Book of Monsters (1914)